摘要
内存分解是数据中心中一项很有前途的技术,具有提高资源利用率、故障隔离和弹性的优势。散列索引已被广泛用于在分布式存储系统中提供快速查找服务。然而,由于内存池中的计算能力太弱,无法执行复杂的索引请求,传统的散列索引对于分类内存来说效率很低。为了在分块内存场景中提供高效的索引服务,提出了RACE哈希,一种具有无锁远程并发控制和高效远程调整大小的单侧RDMA感知可扩展哈希索引。RACE哈希通过仅使用单侧RDMA动词,而不涉及内存池中的任何计算资源,使所有索引操作都能高效执行。为了支持高性能的远程并发访问,RACE哈希利用无锁远程并发控制方案,使不同的客户端能够以无锁方式同时操作内存池中的同一哈希索引。为了以低开销调整哈希表的大小,RACE哈希利用可扩展的远程调整大小方案来减少由可扩展调整大小引起的额外RDMA访问,并允许在调整大小期间并发执行请求。大量实验结果表明,在YCSB混合工作负载中,RACE哈希比最先进的分布式内存哈希索引性能高出1.4-13.7倍。
1. 引言
内存分解引起了工业界(如惠普的机器和英特尔的RSD)和学术界的广泛关注,它将数据中心中传统的单片计算和内存资源分离开来,形成独立的计算和内存资源池。由于资源池和独立的硬件部署,分类内存在资源利用率、故障隔离和弹性方面都有所提高。在分解内存体系结构中,计算刀片运行的应用程序只有少量内存作为缓存。相比之下,内存池存储计算能力较弱的应用程序数据。由于不涉及内存池中的计算资源,快速单侧RDMA网络通常用于从计算刀片到内存池的数据访问。
分布式内存散列索引已经成为许多数据中心应用程序的基本构造块之一,例如数据库和键值存储。随着RDMA在现代数据中心越来越受欢迎,对RDMA搜索友好的(RSF)哈希索引已经得到深入研究,例如FaRM跳房子哈希、皮拉夫布谷鸟哈希和DrTM集群哈希。这些RSF索引通过使用单侧RDMA读取从远程内存中获取数据来执行搜索请求,而不涉及远程CPU。相比之下,插入、删除和更新(IDU)请求被发送到远程CPU,由它们在本地执行。然而,这种机制在新的分解内存架构中无法工作,因为内存池中的计算能力太弱,无法执行上述复杂的IDU请求。事实上,在这些RSF散列索引中,IDU请求可以在计算刀片中执行,方法是使用单侧RDMA写和原子写对远程数据进行操作。但是,我们观察到,由于大量的网络往返和并发访问冲突,在现有的RSF哈希索引中使用单侧RDMA动词执行IDU请求会导致性能显著下降。简而言之,由于以下挑战,为分类内存设计一个高效的散列索引并非易事:
- 许多远程读写用于处理散列冲突。为了处理哈希冲突,现有的哈希方案会产生大量的数据移动开销,为新插入的项目腾出空间,例如跳房子哈希和布谷鸟哈希。这些数据移动是由分解内存中的许多远程读写执行的,这会显著降低哈希索引的性能,因为每次远程读写都会产生一次RDMA网络往返。
- 远程访问的并发控制。为了处理并发访问的冲突,基于锁的技术已被广泛用于散列索引。由于本地执行的纳秒级延迟,锁对于本地散列索引具有低开销。然而,当在分解内存场景中使用锁来散列索引时,必须使用具有微秒级延迟的RDMA原子来实现远程锁定,从而导致高开销,并在发生锁争用时增加等待延迟。特别是对于数据移动过多的哈希索引,在移动数据之前会获取多个锁,这加剧了锁争用。
- 哈希表的棘手远程调整大小。当哈希表已满时,调整大小对于增加其大小是不可避免的。传统的全表调整大小需要将所有键值项从旧哈希表移动到新哈希表。可扩展调整大小由于需要首先访问哈希表的目录,因此以额外的一次RDMA读取为代价,减少了调整大小期间移动的项目数量。此外,在调整大小的过程中,并发访问哈希表具有挑战性。
为了应对上述挑战,据我们所知,我们提出了RACE哈希,这是第一个为分类内存设计的哈希索引,它完全依赖单向RDMA动词来高效执行所有索引请求。为了减少调整大小对性能的影响,RACE哈希利用了可扩展的调整大小,因此RACE哈希表由多个子表和一个用于索引子表的目录组成。子表结构被设计为单侧RDMA意识(RAC),实现了所有索引请求(包括搜索、插入、删除和更新)都可以仅使用单侧RDMA动词来执行,同时在最坏的情况下具有恒定的时间复杂度,因此提供了高性能。为了提高远程并发的性能,RACE哈希利用了RAC哈希子表的无锁远程并发控制方案,实现了除失败的插入之外的所有索引请求都以无锁方式并发执行。此外,为了减少可扩展的大小调整带来的性能损失,RACE哈希在客户端缓存目录(客户端是中央处理器刀片),因此消除了对目录的RDMA访问。然而,由于当哈希表被调整大小时,客户端缓存中的目录变得陈旧,因此通过陈旧的目录缓存访问哈希表可能会获得不正确或不一致的结果。RACE哈希提供了一个简单而有效的陈旧读取方案,以保证访问数据的正确性,并允许在调整大小期间执行当前请求。
具体而言,本文做出以下贡献:
- 片面的RDMA意识表结构。我们提出了一个RAC子表结构,它既支持RDMA搜索,也支持RDMA IDU搜索。所有索引请求都是通过仅使用具有恒定最坏情况时间复杂度的单侧RDMA动词来执行的。IDU请求不会导致任何额外的数据移动。
- 无锁远程并发控制。我们为RACE哈希设计了无锁远程并发算法,使除了失败的插入之外的所有请求都可以在没有锁的情况下并发执行。
- 可扩展远程调整大小。我们提出了一个陈旧读取客户端目录缓存方案,以减少远程目录查找的一个额外RDMA读取,并保证使用陈旧目录缓存时请求执行的正确性。我们还实现了对正在调整大小的子表的并发访问。
- 执行和评价。我们已经实现了RACE哈希并评估了它的性能。大量实验结果表明,在YCSB混合工作负载中,RACE哈希比最先进的分布式内存哈希索引的性能高出13.7倍。
2. 背景和动机
2.1 内存分解
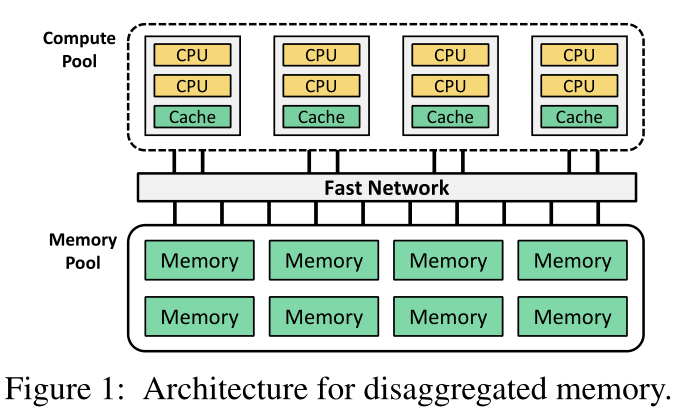
在数据中心的通用分类内存体系结构中,不同类型的资源被分成池,例如计算池和内存池,如图1所示。每个池都是独立管理和扩展的,并且是故障隔离的。计算池由许多CPU刀片组成,每个刀片保留少量内存作为内存池的本地缓存。内存池包括许多内存刀片,可以是动态随机存取存储器,也可以是永久内存内存,内存控制器和控制器(内存控制器和控制器可以是同一个实体)。RNIC和控制器具有仅用于互连的低功率处理单元。计算池和内存池之间的通信利用快速远程访问互连技术,例如单侧RDMA、全路径或Gen-Z。内存池为计算池提供的接口包括读、写、ALLOC和FREEfor可变大小内存块,以及原子操作,例如比较和交换(CAS)以及取加(FAA)。我们假设ALLOC和FREE接口在内存池的RNICs或控制器中实现。不失一般性,本文的其余部分考虑将单侧RDMA用于分解内存体系结构中的互连,即计算刀片使用RDMA读、写和原子访问内存池。
2.2 RDMA搜索友好散列索引
在本小节中,我们首先介绍现有的RDMA搜索友好(RSF)哈希索引,然后分析它们在分类内存上的性能。
2.2.1 现有哈希方案
随着RDMA在现代数据中心的广泛使用,RSF散列索引已经被深入研究。所有这些RSF散列索引都是为具有单片服务器的数据中心架构设计的。客户端通过使用RDMA读取从远程内存获取数据来执行搜索请求,而不涉及远程CPU。相比之下,IDU请求被发送到远程服务器,并使用远程CPU执行。我们详细回顾了这些散列索引中的每一个,如下所示。
Pilaf·Cuckoo散列法:皮拉夫提出了一种3路布谷鸟散列法,它使用3个正交散列函数为每个密钥计算3个不同的散列桶。当执行关键字搜索时,客户端首先使用RDMA读取来读取它的3个相应散列桶中的一个。如果密钥不存在于第一个桶中,则客户端读取第二个散列桶。当在第二个桶中没有找到密钥时,客户端读取第三个散列桶。对于插入请求,客户端将它们发送到服务器,服务器CPU在本地处理它们。插入可以迭代地将布谷鸟散列表中现有的键值项目驱逐到它们的替换位置。这种机制会导致不一致的问题,即当服务器处理其驱逐时,客户端执行的搜索请求可能会错过密钥。为了解决这个问题,服务器首先计算所有受影响的桶(称为杜鹃路径[26]),然后移动键。然后,服务器从布谷鸟路径中最后一个受影响的桶开始,将每个键移动到其备用位置。
FaRM Hopscotch Hashing: FaRM提出了一种链式关联Hopscotch Hashing,其中每个桶都有一个包含桶本身及其后续桶的邻域。每个存储桶都有多个槽,每个密钥都存储在该密钥被散列到的存储桶的邻域中。对于也在服务器端处理的插入,跳房子哈希试图在密钥的哈希桶附近找到一个空槽。如果找到,空槽存储项目。否则,跳跃式散列法通过执行线性探测继续向前寻找空槽。如果找到一个空槽,跳房子哈希算法会尝试迭代地移动项目,将空槽移向邻域。如果没有空槽或移动失败,跳房子哈希会将项目存储在链接到密钥哈希桶的桶列表中。执行搜索时,客户端使用RDMA读取读取密钥散列桶的邻域,即两个相邻的桶。在没有找到密钥时,客户端进一步遍历链接的桶。请注意,遍历每个桶需要一次RDMA读取。
DrTM集群哈希:DrTM中提出的集群哈希是一种具有关联性的链式哈希,其中读写键值项使用RDMA READs和WRITEs,对哈希表的插入和删除被运送到服务器进行本地执行。为了插入一个新的密钥,集群散列试图在密钥的散列桶和链接到密钥散列桶的桶列表中找到一个空槽。如果没有空槽,集群哈希会在桶列表中添加一个新桶来存储插入的键值项。对于搜索请求,客户端使用RDMA读取来读取密钥的散列桶。在没有找到密钥时,客户端进一步逐个遍历链接的桶。
2.2.2 内存分解的表现
据我们所知,目前还没有专门为分类内存设计的散列索引。作为第一步,我们分析在分类内存中使用上述RSF散列索引的性能。由于内存池中缺乏执行IDU请求的计算能力,我们考虑用单侧RDMA动词来实现IDU请求。
对于皮拉夫布谷鸟哈希,要插入键值项目,当哈希表处于高负载系数时,客户端需要执行驱逐操作。具体来说,基于最先进的并发布谷鸟散列算法,客户端首先计算布谷鸟路径,并使用RDMA案例锁定路径中的所有桶。然后,客户端使用RDMA写操作迭代驱逐杜鹃路径中的键值项目。一条杜鹃路径可能包含几十个或几百个桶。因此,插入是通过使用大量的RDMA案例和写操作来执行的,由于使用大量的锁,插入性能很差,并且还会降低其他搜索请求的性能。
对于FaRM hopscotch散列法,要插入一个键值项,客户端需要使用RDMA READs线性探测散列表中的桶,直到找到一个空槽。当哈希表处于高负载系数时,插入一个键可能需要向客户端读取整个哈希表,直到找到一个空槽。在找到一个空槽后,将空槽移向插入的键的邻域也是复杂且昂贵的,这是因为在移动路径中锁定了多个存储桶,并使用多个RDMA写入来移动项目。此外,如果没有空槽或移动失败,添加链接桶的操作也很昂贵。
对于DrTM集群散列,要插入键值项,客户端需要逐个遍历其对应桶列表中的桶,直到找到一个空槽。遍历每个桶需要一次RDMA读取。如果这些存储桶中有一个空槽,客户端将使用RDMA写操作插入该项。否则,客户端会将新的溢出桶添加到桶列表中。在修改桶列表之前,客户端需要锁定桶列表,以防止其他客户端插入重复的密钥或释放桶。因此,插入执行的操作包括遍历桶列表、锁定/解锁、为新桶和新项目分配内存、链接新桶和写入新项目,从而产生许多RDMA读、写和案例。在集群哈希中分配溢出桶的操作比在FaRM hopscotch哈希中更频繁,因为集群哈希处理主哈希表中的哈希冲突的能力较弱。此外,删除请求在链接桶列表的结构中也很复杂,因为需要将项目从列表尾部的桶移动到列表头部的桶,以填充空槽,并回收尾部桶以获得更高的性能和空间利用率。
总之,这些RDMA搜索友好的散列索引对分解内存变得RDMA IDU不友好,因为IDU请求导致大量RDMA操作来处理散列冲突和并发控制。我们的论文提出了RACE哈希算法,它对RDMA搜索友好,对RDMA IDU友好,同时有效地处理哈希冲突和并发控制,如第3节所述。性能也在第4节中得到验证。
2.3 Resize哈希表
当哈希表已满时,即插入失败或其加载因子达到阈值时,需要通过扩展其容量来调整哈希表的大小。一般来说,有两种大小调整机制,包括全表大小调整和可扩展大小调整。
为了扩展散列表,全表调整大小机制分配一个大小比旧散列表大的新散列表,例如两倍大小,然后迭代地将每个键值项从旧散列表移动到新散列表。由于移动了所有项目,调整整个表格的大小非常昂贵。
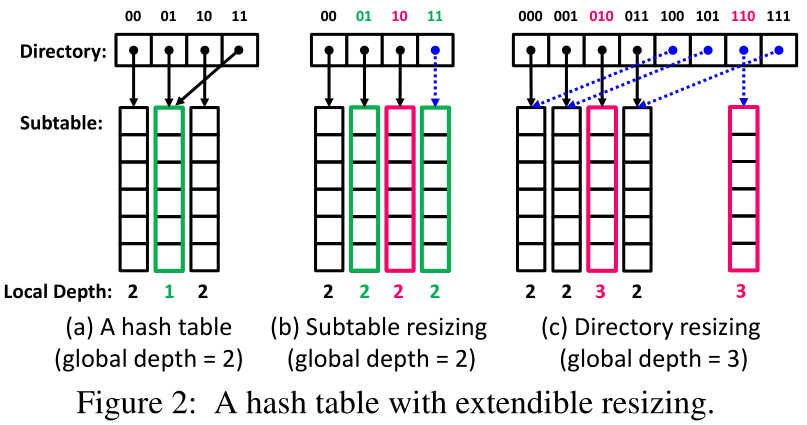
在可扩展的调整大小中,调整大小操作只需要移动部分项目。具体来说,使用可扩展大小调整的哈希表包括多个子表,并且有一个目录来索引这些子表,如图2a所示。对于64位哈希值,目录使用M位来定位子表(我们以最后M位为例,即后缀),剩余(64-M)位用于定位子表中的目标桶。目录当前使用的后缀位数称为全局深度(GD) (GD ≤ M)。因此,该目录有2个条目,最多对应2个子条目。每个子表都有一个局部深度(LD) (LD ≤ GD),表示子表使用的后缀位数。
当子表已满时,我们通过添加一个新的子表将子表分成两部分。如图2a和2b所示,当后缀为“1”的子表已满时,它被分成子表“01”和“11”。调整大小机制将后缀为“11”的键从子表“01”移动到子表“11”,并将它们的LDs更改为2。当一个子表已满,并且它的LD等于GD时,我们通过将其大小增加一倍来增加目录,如图2b和2c所示。完整的子表被分成两个子表。除了添加的新子表对应的目录条目之外,其他新目录条目都指向它们对应的原始子表。在调整目录大小时,搜索请求使用新的GD来定位它们相应的子表。总之,通过执行可扩展的大小调整,当一个子表已满时,我们只需要调整这个子表的大小,而不会影响其他子表中的键值项。因此,RACE哈希使用可扩展的大小调整。
然而,在分类内存中使用可扩展的大小调整有两个挑战。首先,与全表调整大小相比,可扩展调整大小会为每个搜索请求带来一次额外的内存访问,因为在访问子表之前需要首先查询目录以获取tar- get子表的地址。由于快速的本地内存访问,一次额外的内存访问对本地哈希表的性能几乎没有影响。但是,在分类内存中,一次额外的内存访问会产生一次RDMA往返,从而显著降低搜索性能。第二,由于分解内存中没有强大的计算资源来执行复杂的调整大小,调整大小必须由远程客户端(即中央处理器刀片)触发和执行,这不同于总是由本地中央处理器执行的传统调整大小机制。当一个客户端执行大小调整时,其他客户端不知道它的发生。因此,我们必须在调整大小的过程中处理对哈希表的并发访问。
3. RACE哈希
3.1 概述
图3显示了用于分类内存的RACE哈希的整体架构。RACE哈希表存储在内存池中。计算池中的客户端使用单侧RDMA动词来操作哈希表。为了减轻调整大小对性能的影响,RACE哈希利用了可扩展的调整大小,因此哈希表由多个子表和一个目录组成。为了减少访问远程目录的额外RDMA读取,RACE哈希利用了客户端的目录缓存1。每个客户端维护一个本地缓存,只存储RACE哈希表的目录。因此,客户端可以使用本地内存访问而不是远程RDMA读取来访问目录,并使用RDMA动词来仅访问子表。我们在第3.2节中介绍了一个RDMA意识(RAC)散列子表结构的设计,即RAC散列子表,其中所有索引请求都是通过仅使用单侧RDMA动词来执行的,同时具有恒定的最坏情况时间复杂度。然后,我们在第3.3节中为RAC哈希子表提出了一个无锁远程并发控制方案,实现了包括搜索、插入、删除和更新在内的索引请求以无锁方式并发执行。此外,在客户端缓存目录会导致内存池和客户端缓存中的目录之间出现数据不一致的问题。
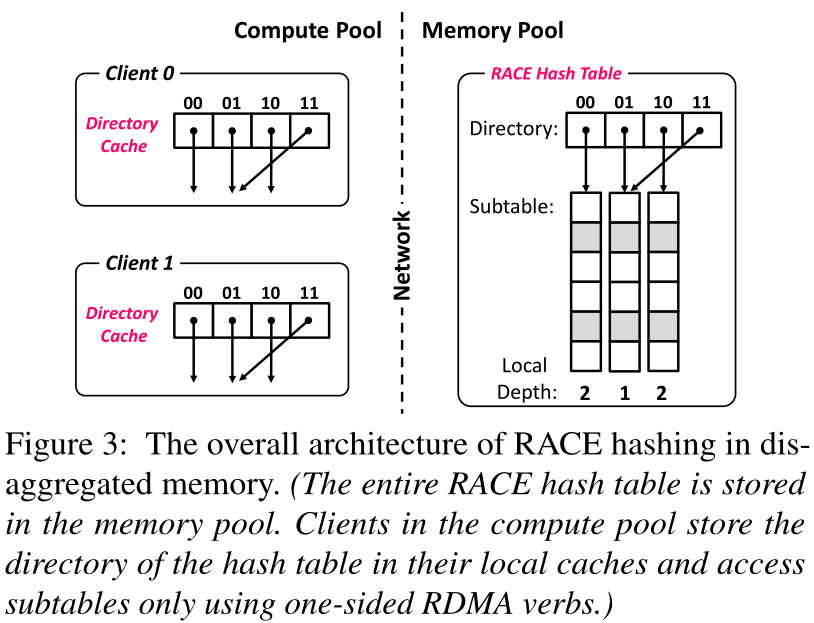
因此,我们最终在第3.4节中提出了一个带有过时读取方案的客户端目录缓存,以低开销解决不一致性问题。
3.2 RAC散列合适的结构
在分解内存场景中,设计RAC哈希子表结构的挑战来自于在保持高内存效率和搜索性能的同时,最大限度地减少IDU请求的远程RDMA操作的数量。为了实现这一目标,我们设计了RAC哈希子表,它不允许任何移动操作、驱逐或桶链接来处理哈希冲突,因为这些操作会导致大量远程写入,如第2.2节所述。相反,RAC哈希子表使用三种主要的设计选择,包括关联性、两种选择和溢出托管,来解决哈希冲突,从而为所有索引请求实现恒定的最坏情况时间复杂度。
1)关联性。通过关联性,每个桶有多个槽,能够存储多个键值项目。K路关联性意味着每个存储桶都有K个插槽。关联性对于单侧RDMA操作是友好的,因为一个桶中的多个项目可以在一个RDMA读取中一起读取。图4显示了一个带有4路关联性的RAC哈希子表。
2)两种选择。基于“两个选择的力量”理论[32],使每个密钥对其存储位置有两个选择可以在桶之间实现良好的负载平衡,从而有效地处理哈希冲突。因此,RAC子表使用两个独立的散列函数h1()和h2(),为每个键计算两个散列位置,如图4所示。通过将关联性与两个选项有效地结合起来,RAC子表会在两个散列位置之间的负载较小的桶中插入一个新项。请注意,根据Mitzenmacher的观察[32],两个选择比一个选择实现了负载平衡效率的指数级提高,而三个选择比两个选择只有恒定的因子提高。在分类内存中,三个选择比两个选择多一个桶访问(即多一个RDMA读取)。因此,与使用三个选择的皮拉夫[31]不同,我们在设计中使用两个选择。
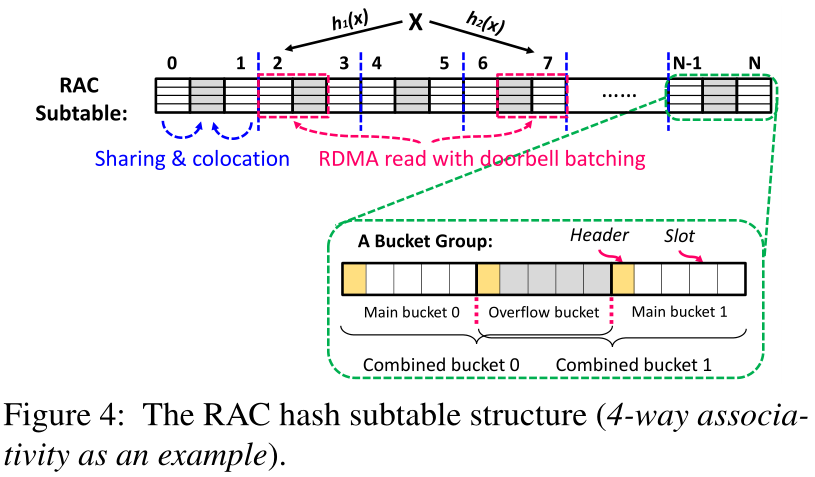
3)溢出托管。溢出共享技术[46]使一个溢出桶(或称为备用桶)能够被其他两个主桶共享,以存储冲突项,从而实现更好的负载平衡。然而,溢出桶与它们的主桶是分离的[46],导致额外的桶访问,由于额外的RDMA读取,这对于分解内存来说表现更差。为了解决这个问题,我们提出了一个溢出托管方案来存储与其主桶相邻的溢出桶。如图4所示,三个连续的桶被视为一个组,其中第一个和最后一个桶是主桶,可以通过哈希函数寻址。中间桶是一个溢出桶,哈希函数无法寻址它,第一个桶和最后一个桶共享它来存储它们冲突的项目。通过这样做,一个RDMA读可以获取一个主桶和它的溢出桶,从而减少RDMA读的数量。
将所有这些放在一起,RAC哈希表的结构如图4所示。RAC哈希子表是存储在连续内存空间中的一维桶数组。每个桶都是K路关联的,一个桶组包括三个连续的桶,即两个主桶和一个共享的溢出桶。主铲斗及其溢流铲斗的组合称为组合铲斗。对于每个密钥,我们计算分别位于两个不同桶组中的两个散列位置。RAC哈希子表的结构简单,但对于分解内存很有效,具有以下优点:
- RDMA-IDU友好:由于每个键只涉及两个组合桶,IDU请求只需要在这两个组合桶内操作,而无需将项目从/驱逐到其他桶或链接新桶,具有恒定的最坏情况时间复杂性,同时对RDMA友好。
- RDMA-搜索友好:一个搜索请求只发出两个RDMA读取,每个读取一个组合桶。更重要的是,两个RDMA读取可以并行发出,以减少请求延迟,这不同于群集哈希[44],在群集哈希中,发出下一个RDMA读取必须等待前一个读取的返回才能遍历链接的存储桶。此外,通过使用门铃批处理[22],这是一种在一个RDMA往返时间(RTT)内读取多个不相交存储区域的read优化技术,我们将两个RDMA读取操作打包成一个。因此,RAC子表中的搜索延迟是一个RTT,而不是两个。
- 高内存效率:通过结合关联性、两个选择和溢出托管,RAC哈希子表使项目能够更均匀地分布在存储桶中,从而有效地处理哈希冲突,实现良好的负载平衡。因此,根据第4.2.1节的评估,它实现了高达90%的高负载系数(具有7向关联性)。
3.3 无锁远程并发控制
基于锁的技术已被广泛用于单台机器内的现有散列索引,以实现并发控制[15,26]。然而,对于分类内存,所有请求都是通过使用单侧RDMA动词来执行的,这给处理并发访问冲突带来了不小的挑战。这是因为,与纳秒级延迟的本地锁定相比,使用微秒级延迟的RDMA cass实现的远程锁定会产生更高的开销,并且每次锁定或解锁操作都需要RDMA往返。为了提供高并发性能,我们提出了一种用于RACE散列的无锁远程并发控制方案,该方案实现了除了失败的插入之外的所有索引请求都成为无锁的。插入失败会触发子表调整大小,需要获取调整大小锁,如第3.4.2节所述。
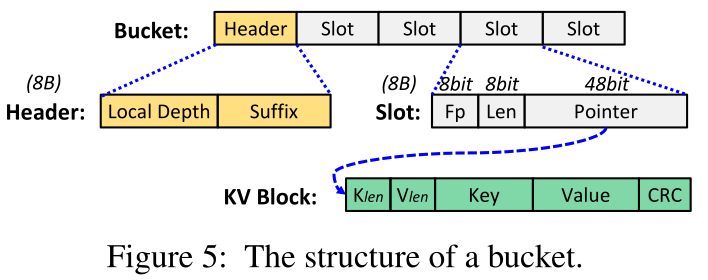
桶结构。在RACE哈希中,为了支持可变长度的键和值,完整的键值项存储在哈希表之外,就像现有的哈希索引[10,31,44]一样。指向完整键值项的指针存储在哈希表中。RAC哈希子表中每个桶的结构如图5所示。一个存储桶由一个集管和多个插槽组成。标题用于哈希表的大小调整,将在第3.4.1节中介绍。每个槽对应一个键值项目。为了支持无锁远程并发访问,插槽是8B,即RDMA CAS的最大大小,由指纹(8位)、键值长度(8位)和指针(48位)组成。指纹(Fp)是密钥的8位散列。根据对现有工作的分析[15],8位指纹足以实现非常低的假阳性(假阳性意味着桶中不同的密钥具有相同的指纹)。此外,在使用RDMA READ读取完整的键值项目之前,我们需要知道项目的大小。因此,我们将键值块的长度(Len)存储在槽中。长度为8位,长度单位为64B2。因此,键值块的长度总是64B的倍数,键值块的最大长度是28∫64B = 16KB,这涵盖了当前键值存储的大多数应用场景,因为小键值在其中占主导地位[7]。当键值项目大于16KB时(这实际上很少发生),我们将超过16KB的剩余项目内容存储在第二个键值块中,并将第二个块链接到第一个块。密钥和值(即Klenand Vlen)的各自长度存储在密钥-值块的头部。插槽中的指针消耗48位,就像x86_64系统[10,34,43]一样。空指针表示插槽为空。基于桶结构,我们在下面给出了无锁搜索/插入/删除/更新操作。
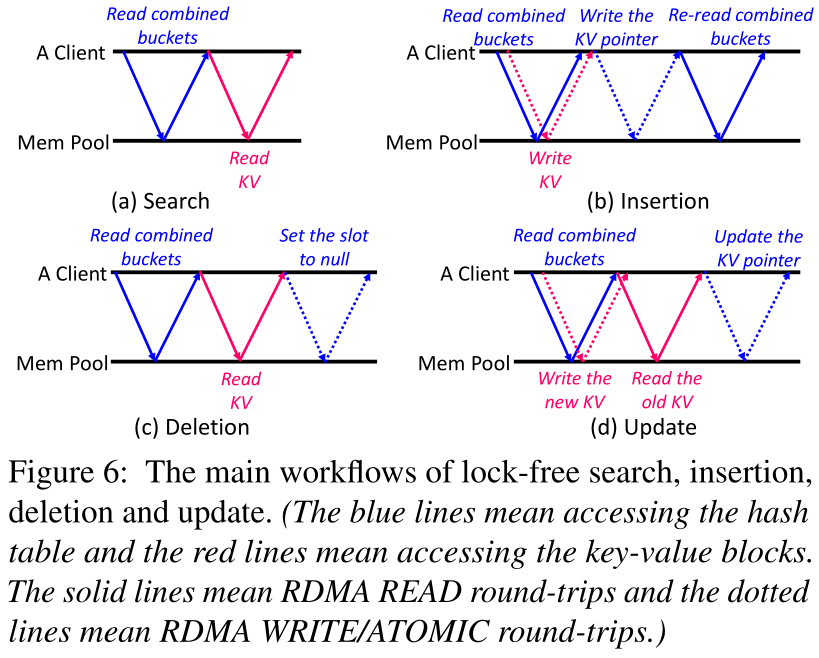
无锁插入。为了插入键值项目,客户端使用门铃批处理来读取与该键对应的两个组合桶。同时,客户端将键值块3写入内存池。因此,读取桶和写入键值块是并行执行的,如图6b所示。一旦接收到合并的桶,客户机就按照主桶第一和溢出桶第二的顺序寻找一个空槽,如第3.2节所示。如果发现一个空槽,客户端使用RDMA CAS将键值块的指针写入其中。否则,会触发哈希表调整大小,如第3.4节所示。
在极少数情况下,客户端可能同时向哈希表中插入重复的键,因为RDMA原子性只确保8B原子性。例如,客户端1和客户端2试图插入相同的密钥K。由于每个密钥对应于RACE哈希中的两个组合桶,因此可能会出现客户端1选择组合桶0中的一个空插槽来插入K,而客户端2选择组合桶1中的一个空插槽来插入K的情况。在这种情况下,哈希表中存在两个重复的密钥K。为了解决重复键的问题,在将指针写入桶中进行插入后,客户端重新读取两个组合的桶来检查重复键,如图6b所示。在查找重复密钥时,客户端只保留一个有效密钥,并删除剩余的重复密钥。不同的客户端在查找重复密钥时必须确定相同的键值项作为有效密钥,以保证并发访问的一致性。为了保证这一点,我们因此在算法中达成一致,为不同的客户端确定唯一有效的密钥。例如,在两个组合桶中,协议认为存储在具有最小桶号和最小槽号的槽中的密钥是唯一有效的密钥。
无锁定删除。要删除键值项目,客户端首先执行搜索来查找目标键。如果找到目标密钥,客户端通过使用RDMA CAS将其对应的插槽设置为空,如图6c所示。一旦RDMA CASis成功完成,删除请求将被返回。然后,客户端将键值块设置为全零,并在后台释放键值块。如果RNIC为了数据安全可以自动将释放的内存设置为全零,即避免旧数据被其他客户端观察到,则可以避免置零操作。
无锁定更新。为了更新键值项目,客户端搜索目标键。同时,客户端将新的键值项写入内存池,如图6d所示。一旦找到目标密钥,客户端就使用RDMA CAS来更改插槽的内容,以指向新的密钥-值项。如果RDMA CAS成功执行,将返回更新请求。客户端最终在后台释放旧的键值块。
无锁定搜索。如图6a所示,为了搜索一个关键字,客户机读取它对应的两个组合桶。如果指纹与其中一个插槽匹配,客户端将读取该插槽指向的键值块。客户端然后比较完整的密钥。如果全键匹配,则返回该值。
由于桶上的所有修改都是原子的,并且更新请求不会就地修改旧的键值项,因此搜索的唯一不一致情况是在搜索请求读取键值块之前(在获得键值的指针之后)释放或重新分配键值块。然而,通过将存储在块中的密钥的长度和内容与搜索密钥的长度和内容进行比较,可以容易地观察到这种不一致的情况。这是因为一旦键值块被释放/重新分配,它的内容就会被完全清零/改变,从而导致比较不匹配。然而,仍然存在一种特殊情况,即另一个客户端重新分配键值块,并发出RDMA写操作,以写入与旧键值块相同的键、键长度和值长度。由于RDMA写不是原子的,它可能完全写密钥和密钥长度,但在写值。此时,如果读取键值块,客户端可以找到匹配的键。但是价值被打破了,客户无法观察到。为了解决这个问题,我们在每个键值块中添加一个64位校验和,以增强自我验证,并检查像皮拉夫[31]这样的键值块的完整性,如图5所示。皮拉夫还表明,64位校验和足以进行验证。
此外,对于插入、删除和更新请求,CaSe a插槽的操作可能会失败,这意味着该插槽在CAS之前被另一个客户端更改。在这种情况下,RACE哈希会重新搜索目标密钥,然后重新执行失败的插入、删除或更新请求。
3.4 可扩展远程resize
对分解内存使用可扩展的大小调整会带来两个挑战,即每个索引请求读取目录的额外远程访问和调整大小期间的并发访问,如第2.3节所述。在这一小节中,我们提出了一个过时读取的客户端目录缓存方案和一个在调整大小期间的并发访问方案,以分别解决这两个挑战。
3.4.1 读取过时的客户端目录缓存
为了减少访问目录的额外RDMA读取,我们使用客户机目录缓存进行RACE散列。但是,在客户端缓存目录会导致内存池和客户端缓存中的目录之间的数据不一致问题。例如,当客户端触发子表大小调整或目录大小调整时,内存池中目录的内容会被修改,因此其他客户端缓存中的目录会变得陈旧。如果其他客户端仍然使用它们的旧目录查询哈希表,它们可能会找到不正确的子表并获得不正确的数据。
为了解决客户端缓存和内存池之间的不一致问题,在基线解决方案[17]中,当客户端触发调整大小操作时,客户端向所有其他客户端广播通知消息,以使它们各自的目录缓存无效,并且直到接收到所有其他客户端的确认时才开始修改内存池中的目录。显然,由于广播消息和等待所有确认,基线解决方案会导致调整大小的高性能开销。皮拉夫[31]提出的第二个解决方案是关闭所有其他客户端的RDMA连接,以防止这些客户端在触发大小调整后执行RDMA读取。在调整大小完成后,客户端重新连接内存服务器以获取新的表根。皮拉夫解决了不正确访问的问题,但由于阻止客户端的RDMA读取而导致高性能损失。因此,这两种解决方案都会产生巨大的性能开销。
为了有效地解决这种不一致性问题,我们提出了一种陈旧读取客户端目录(SRCD)缓存方案,该方案在触发大小调整时不需要广播消息或关闭其他客户端到内存池的连接。相反,通过使用SRCD缓存方案,客户端仍然使用缓存中的旧目录来查询哈希表,但可以验证获得的数据是否正确。为了实现这一点,我们在RAC哈希子表的每个桶中添加一个头,如图5所示。桶标题存储桶所属子表的本地深度和后缀位。在IDU请求中,桶头不会被修改,只有在创建子表并调整其大小时才会被修改。桶标题中的本地depthand后缀位用于在执行搜索/插入/删除/更新时验证桶是否正确。
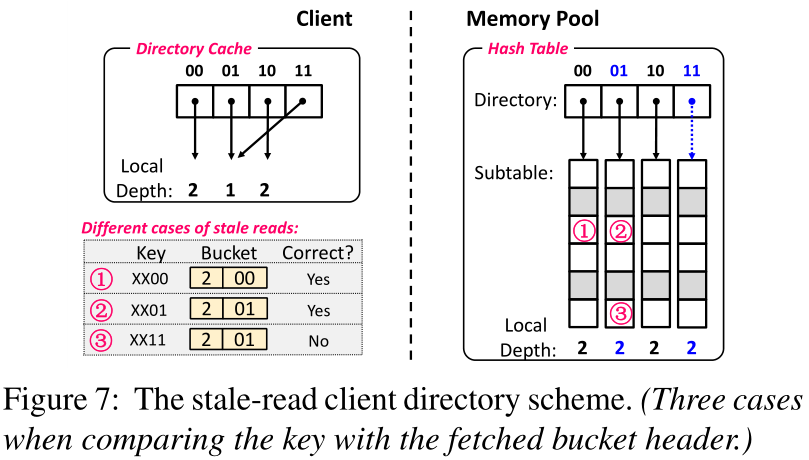
图7显示了使用SRCD缓存方案来验证存储桶正确性的示例。客户端当前缓存了哈希表的目录,如图2a所示,其中目录条目“01”和“11”指向同一个子表。在内存池中,哈希表的大小被调整为新的哈希表,如图2b所示,其中创建了一个新的子表,目录条目“01”和“11”指向不同的子表。为了搜索关键字,客户端首先使用具有陈旧读取的SRCD缓存来定位子表,然后通过RDMA读取来获取该子表中的存储桶。在接收到桶之后,客户端分别将存储在桶头中的本地深度和后缀位与SRCD缓存中目录条目的本地深度和密钥的后缀位进行比较。客户可以观察到以下三种情况。
1)本地深度和后缀位都匹配。如果桶头中的本地深度和后缀位分别与缓存中目录条目的本地深度和密钥的后缀位相同,则客户端可以验证子表没有调整大小,并且提取的桶是正确的。例如,关键字是“XX00”,对应于目录条目“00”,即图7中的案例x。
2)局部深度不匹配和后缀位匹配。如果存储桶头中的本地深度与缓存中目录条目的深度相同,则客户端知道被访问的子表在内存池中已调整大小。客户端进一步使用存储在桶头部中的本地深度来计算密钥的后缀位,并且发现密钥的后缀位和存储在桶头部中的后缀位匹配。在这种情况下,客户端可以验证存储桶是否正确,尽管子表的大小已经调整。例如,键是“XX01”,但是子表“01”在内存池中被调整了大小,即图7中的案例y。在调整大小的过程中,带有“11”的键被移出子表“01”,而带有“01”的键仍保留在子表“01”中。因此,当定位子表“01”来搜索带有“01”的关键字时,客户端可以获得正确的键值项。
3)本地深度和后缀位都不匹配。如果桶标题中的本地深度和后缀位不匹配,客户端可以验证子表的大小是否被调整,并且搜索到的关键字是否应该存储在新的子表中。例如,关键字“XX11”对应于缓存中的目录条目“01”,但是子表“01”在内存池中被调整大小,并且关键字“XX11”被移动到新的子表“11”,即图7中的案例z。在这种情况下,客户端从内存池中获取新的目录条目,并重新执行搜索。
总之,只有在“3)本地深度和后缀位都不匹配”的情况下,客户端才需要获取新的目录条目并更新本地目录缓存。在其他情况下,客户端可以通过过时的读取来定位正确的存储桶。
3.4.2 resize期间的并发访问
当插入失败时,会触发子表调整大小。在调整大小的过程中,我们需要将槽从调整大小的子表移动到新的子表。由于槽的移动,保证正在调整大小的子表上的并发搜索、插入、删除和更新请求的正确执行是一项挑战。为了应对这一挑战,我们设计了如下并发调整大小的工作流程。
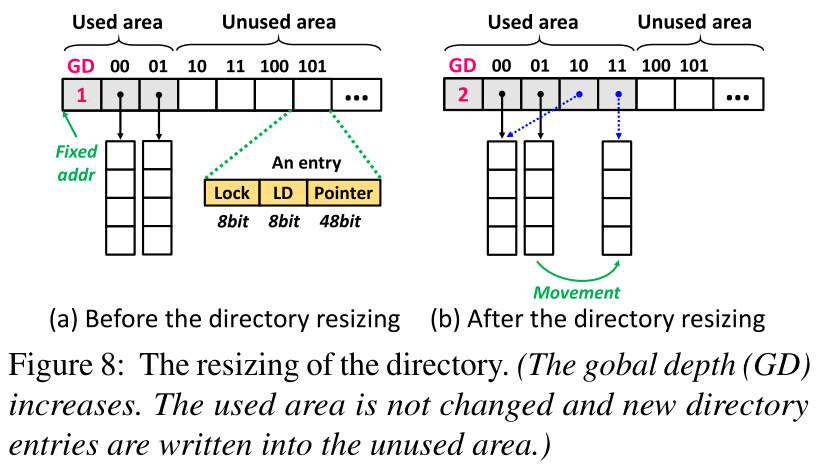
为了在调整大小时支持并发访问,不能更改内存池中目录的起始地址。否则,客户端在调整大小后无法找到新的哈希表。因此,我们保留了足够大的连续内存空间4,用于将来调整目录的大小。如图8所示,目录包括一个已用区域和一个未用区域。客户端只缓存已用区域。为了调整目录的大小,例如,将GD从1增加到2,使用的区域不改变,并且新的目录条目被写入未使用的区域。
要调整子表的大小,客户端首先锁定内存池中子表的目录条目。锁定仅防止其他客户端调整同一子表的大小,但不防止其他客户端在子表中执行搜索和IDU请求。客户端创建一个新的子表,并初始化新子表中每个桶的头。客户端进一步将新子表的指针写入目录,同时锁定目录条目。然后,客户端开始移动项目。图8b显示了一个例子。客户端将后缀为“11”的项目从子表“01”移动到子表“11”。子表“01”中每个桶的移动包括三个步骤:将桶头中的后缀位从“1”更新为“2”(一个RDMA CAS);将该桶中后缀为“11”的所有项目插入子表“11”(一个或多个RDMA案例);删除此时段中后缀为“11”的所有项目(一个或多个RDMA案例)。通过保证执行这三个步骤的顺序,我们支持对正在调整大小的子表的并发访问。下面,我们讨论如何处理由下面的并发调整大小引起的角点情况。
- 并发搜索:在执行搜索时,如果发现本地深度和后缀位都不匹配,客户端可以感知到子表“01”中发生了大小调整。在这种情况下,移动可能在步骤之前,也可能在步骤之后。如果在读取桶中找到目标键,则表示移动在步骤之前。否则,移动在步骤之后或者键不存在。客户端进一步读取子表“11”中的桶来查找目标键。
- 并发插入:在插入过程中,客户端重新读取桶来检查重复的键,如图6b所示。为了在调整大小时支持并发插入,我们还会在重新读取插入键的存储桶后检查存储桶头。如果桶头没有改变,则插入成功。否则,客户端知道桶中发生了大小调整。然后,客户端将新桶头中的后缀位与插入的密钥中的后缀位进行比较。如果后缀位匹配,插入也成功。否则,客户端从子表“01”中移除指针,并将键重新插入子表“11”。此外,在调整子表大小时,插入可能会失败,即在子表中找不到空槽。在这种情况下,插入失败会触发下一次调整大小。下一次调整大小将被阻止,直到上一次调整大小释放目录条目锁定。
- 并发删除/更新:执行删除/更新时,如果发现本地深度和后缀位都不匹配,客户端等待移动完成,然后从新的子表中删除/更新密钥。如果后缀位匹配,并且步骤发生在删除/更新的RDMA CAS操作之前,则有两种情况。首先,如果删除/更新的RDMA CAS失败,则意味着该项已被移动到新的子表中。客户端将在新的子表中重做删除/更新请求。第二,删除/更新成功的RDMA案例。但是执行调整大小操作的客户端未能在步骤中删除一个项目,这意味着另一个客户端删除/更新了该项目。执行调整大小的客户端进一步清除新子表中项目的指针,并重新执行项目移动。
总之,在调整子表大小时,所有的搜索/更新/删除和对子表的大多数插入请求都以无锁方式同时执行。由于触发下一次调整大小,只有失败的子表插入被阻止。
4. 性能评估
5. 讨论
并发正确性。RACE哈希遵循没有丢失密钥的并发正确性条件[30]:“无论并发写入器如何,get(K)操作都必须为K返回正确的值”。具体来说,当搜索和更新同时运行时,搜索可以返回新值或旧值,而这两个值都应该是连续的和原子的。当搜索和删除同时运行时,搜索可能不返回将被删除的键或值。
执行resize。在我们当前的实现中,触发调整大小的客户端自己执行调整大小。为了改进实现,客户端可以创建一个后台客户端/线程来执行大小调整。
硬件故障。在分解内存架构中处理硬件故障,包括网络故障、内存故障和客户端CPU故障,既复杂又困难。例如,锁定目录条目后,客户端会失败。为了处理这种失败,我们需要让其他客户端能够感知到失败的客户端,并释放锁目录条目或使用基于租约的锁[44]。我们的论文主要集中在分类内存散列索引的设计上,并计划在未来的工作中扩展RACE散列来支持硬件故障的处理。
6. 相关工作
内存分解。由于为数据中心提供了资源利用和扩展方面的显著优势,内存分解最近受到了广泛关注。现有工作研究数据中心中支持内存分解的各种组件,包括操作系统[38]、硬件架构[28,29]、内存管理[4,37,40–42]、网络[1,9,12,39]和新要求[5,18]。RACE哈希侧重于设计与这些工作正交的分类内存中的索引结构。
在RDMA上散列索引。随着RDMA在现代数据中心的广泛使用,对RDMA搜索友好的散列索引已经得到深入研究[13,31,44]。这些散列索引是为传统的单块服务器设计的,但是由于在执行IDU请求时会产生大量的RDMA操作,因此无法在新的分解内存体系结构上有效工作。RACE哈希是第一个为分类内存设计的哈希索引,其中所有索引请求都可以通过仅使用单侧RDMA操作来有效执行。此外,KV -direct [24]利用带FPGA的可编程网卡来卸载哈希索引操作,这与我们的论文正交,该论文不在FPGA上回复。
并发散列索引。提出了不同的并发散列索引来提供高访问吞吐量。MemC3 [15]使用一个全局锁来实现并发杜鹃散列的多读取器和单写入器并发。Libcukoo [26]利用细粒度锁定来实现多读取器和多写入器并发杜鹃哈希。现有的工作[10,33,46]也提出了持久内存的并发散列索引。然而,所有这些现有的方案都集中在对本地存储器的并发访问上。与它们不同,我们的RACE哈希解决了在哈希索引中并发访问远程内存的挑战,并支持以无锁方式执行所有索引请求。
7. 总结
该文提出了RACE哈希,一种单边RDMAconscious可扩展哈希索引,用于具有无锁远程并发控制和高效远程调整大小的分块内存。哈希表结构被设计为单侧RDMA意识,实现了所有索引请求都可以仅使用单侧RDMA动词来执行,同时以恒定规模的最坏情况时间复杂度提供高性能。此外,RACE哈希利用无锁远程并发控制方案,使索引请求能够以无锁方式并发执行,并利用陈旧读取客户端目录缓存方案,减少一次额外的RDMA读取来访问目录,同时保证陈旧缓存读取的正确性。我们还实现了对正在调整大小的子表的并发访问。实验结果表明,在YCSB混合工作负载中,RACE哈希比最先进的分布式内存哈希索引性能提高了13.7倍。