摘要
我们介绍了Kuco,一种新颖的直接访问文件系统架构,其主要目标是可伸缩性。Kuco利用三种关键技术——协作索引、两级锁定和版本控制读取——将耗时的任务(如路径名解析和并发控制)从内核转移到用户空间,从而避免了内核处理瓶颈。在Kuco的基础上,我们提出了KucoFS的设计和实现,并通过实验证明了KucoFS在广泛的实验范围内具有良好的性能;重要的是,在元数据操作方面,KucoFS比现有的文件系统有更好的扩展性,可以达到一个数量级,并且可以充分利用设备带宽进行数据操作。
1. 引言
新兴的可字节寻址持久存储器(PM),如PCM、ReRAM和最近发布的Intel Optane DCPMM,提供接近DRAM的性能和类似于磁盘的数据持久性。这种高性能硬件增加了重新设计高效文件系统的重要性。在过去的十年里,系统社区已经提出了许多文件系统,如BPFS、PMFS和NOVA,以最小化由传统文件系统架构引起的软件开销。但是,这些PM感知的文件系统是操作系统的一部分,应用程序需要进入内核才能访问它们,其中系统调用和虚拟文件系统(VFS)仍然会产生不可忽略的开销。在这方面,最近的研究提出在用户空间中部署文件系统直接访问文件数据(即DAX),从而利用PM的高性能。
尽管做出了这些努力,我们发现另一个重要的性能指标——可伸缩性——仍然没有得到很好的解决,特别是当多核处理器遇上快速PM时。NOVA通过对内部数据结构进行分区和避免使用全局锁,提高了多核可伸缩性。但是,我们的评估表明,由于VFS层的存在,它仍然不能很好地伸缩。更糟糕的是,一些用户空间文件系统设计通过引入集中式组件进一步加剧了可伸缩性问题。例如,Aerie通过向具有更新元数据权限的可信进程(TFS)发送昂贵的进程间通信(IPC)来确保文件系统元数据的完整性。另一个例子是Strata,它通过直接在PM日志中记录更新,避免了在正常操作中集中处理,但需要一个KernFS将更新(包括数据和元数据)应用到文件系统中,这将导致再次进行数据复制。两个文件系统中的可信进程(如TFS或KernFS)也负责并发控制,这不可避免地成为高并发下的瓶颈。
在本文中,我们通过引入内核-用户空间协作体系结构(Kuco)来重新审视文件系统设计,以实现直接访问性能和高可伸缩性。Kuco遵循经典的客户端/服务器模型,包含两个组件,包括一个用户空间库(名为Ulib),用于提供基本文件系统接口,以及一个位于内核中的可信线程(名为Kfs),用于处理由Ulib发送的请求并执行关键更新(例如,元数据)。
受分布式文件系统设计的启发,例如AFS,它通过最小化服务器负载和减少客户端/服务器交互来提高可伸缩性,Kuco提出了一种新颖的任务划分和Ulib与Kfs之间的协作,它将大多数任务转移到Ulib,以避免Kfs可能出现的瓶颈。为了实现元数据的可伸缩性,我们引入了一种协作索引技术,允许Ulib在向Kfs发送请求之前执行路径名解析。通过这种方式,Kfs可以使用由Ulib提供的预先定位的地址直接更新元数据项。对于数据的可伸缩性,我们首先提出了一个两级锁机制来协调并发写入共享文件。具体来说,Kfs管理每个文件的写租约,并将其分配给打算打开该文件的进程。相反,这个进程中的线程在用户空间中使用范围锁来锁定文件。其次,我们引入了一个版本化的读协议来实现直接读,即使不与Kfs交互且存在并发写入器。
Kuco还包括加强数据保护和提高基线性能的技术。Kuco以只读模式将PM空间映射到用户空间,以防止有bug的程序破坏文件数据。用户空间的直接写是通过一个三相写协议来实现的。在Ulib写入文件之前,Kfs通过切换页表中的权限位,将相关的PM页面从只读切换到可写。在编写文件时,还使用了一种预分配技术来减少Ulib和Kfs之间的交互。
利用Kuco架构,我们构建了一个名为KucoFS的PM文件系统,它获得了用户空间直接访问性能,同时提供了高可伸缩性。我们通过文件系统基准测试和实际应用来评估KucoFS。评估结果表明,在高竞争的工作负载下(例如,在同一个目录中创建文件或在一个共享文件中写入数据),KucoFS比现有文件系统的扩展性好一个数量级,并且在低竞争的情况下提供略高的吞吐量。对于正常的数据操作,也会影响PM设备的带宽。综上所述,我们做出了以下贡献:
- 我们对最先进的PM感知的文件系统进行了深入的分析,并总结了它们在解决软件开销和可伸缩性问题方面的局限性。
- 我们引入了Kuco,这是一种用户空间-内核协作体系结构,具有三种关键技术,包括协作索引、两级锁定和版本化读取,以实现高可伸缩性。
- 基于Kuco架构,我们实现了一个名为KucoFS的PM文件系统,实验表明,KucoFS在元数据操作方面达到了一个数量级以上的可伸缩性,并充分利用PM带宽进行数据操作。
2. 动机
在过去的十年中,研究人员已经开发了许多PM文件系统,如BPFS、SCMFS、PMFS、HiNFS、NOVA、Aerie、Strata、SplitFS、ZoFS。它们大致分为三类。首先,内核级文件系统。应用程序通过捕获到内核中进行数据和元数据操作来访问它们。第二,用户空间文件系统(例如,Aerie、Strata和ZoFS)。其中,Aerie依赖于可信进程(trusted process, TFS)来管理元数据,并保证元数据的完整性。TFS还通过分布式锁服务协调对共享文件的并发读写。相反,Strata允许应用程序直接将更新附加到每个进程的日志中,但需要后台线程(KernFS)将记录的数据异步地消化到存储设备中。ZoFS避免使用集中式组件,并允许用户空间应用程序在名为Intel Memory Protection Key (MPK)的新硬件特性的帮助下直接更新元数据。请注意,Aerie、Strata和ZoFS仍然依赖于内核来执行粗粒度的分配和保护。第三,混合文件系统(例如,SplitFS和我们提议的Kuco)。SplitFS提供了用户空间库和现有内核文件系统之间的粗粒度分割。它完全在用户空间中处理数据操作,并通过Ext4文件系统处理元数据操作。表1总结了现有的PM感知文件系统,以及它们在各个方面的表现。
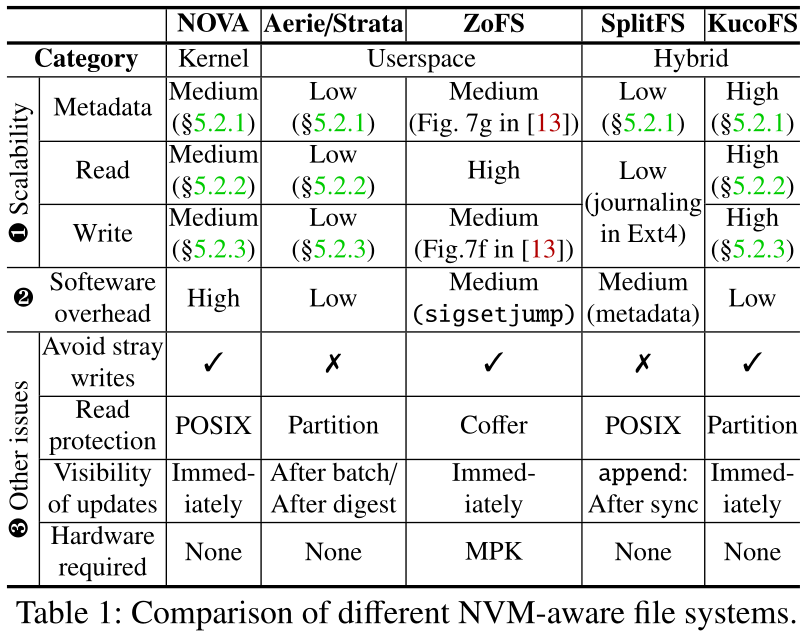
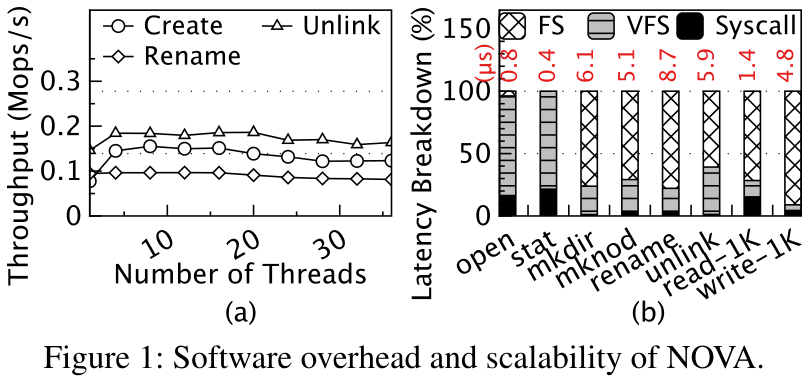
- 多核的可伸缩性。NOVA是一种最先进的PM内核文件系统,经过精心设计,通过引入逐核分配器和逐inode日志来提高可伸缩性。然而,VFS仍然限制了它对某些操作的可伸缩性。我们通过在Intel Optane DCPMM上部署NOVA(详细的实验设置见§5.1),并使用多个线程在同一个目录中创建、删除或重命名文件的实验证明了这一点。如图1a所示,随着线程数量的增加,它们的吞吐量几乎没有变化,因为VFS需要获取父目录的锁。Aerie依赖于一个集中的TFS来处理元数据操作和执行并发控制。虽然Aerie通过批量修改元数据来减少与TFS的通信,但§5中的评估显示,TFS仍然不可避免地成为高并发下的瓶颈。在Strata中,KernFS需要在后台消化日志数据和元数据。如果应用程序的日志完全用完,它必须等待正在进行的摘要完成,然后才能回收日志空间。因此,消化线程的数量限制了Strata的整体可伸缩性。Aerie和Strata都通过昂贵的IPC与可信进程(TFS/KernFS)交互,这将引入额外的系统调用开销。ZoFS不需要集中式组件,因此可以实现更高的可伸缩性。然而,当处理需要从内核分配新空间的操作时(例如,create和append,参见他们论文中的图7d、7f和7g), ZoFS仍然不能很好地扩展。我们的评估表明,SplitFS对于数据和元数据操作的伸缩性都很差,因为它1)不支持不同进程之间的共享,2)依赖于Ext4更新元数据(见图7和图9)。
- 软件开销。在内核中放置文件系统会面临两种类型的软件开销,即系统调用和VFS开销。我们仍然通过分析NOVA来研究这种开销,在NOVA中我们收集了常见文件系统操作的延迟分解。每个操作都用一个线程在100万个文件或目录上执行。我们从图1b中得到两个观察结果。首先,系统调用占用总执行时间的21%(例如stat和open)。另外,在一个进程进入内核后,操作系统可能会安排其他任务,然后将控制权返回给原来的进程。因此,系统调用为对延迟敏感的应用程序带来了额外的不确定性。其次,Linux内核文件系统是通过覆盖VFS函数来实现的,而VFS会导致不可忽视的开销。虽然最近的PM文件系统使用直接访问(DAX)绕过VFS中的页面缓存,但我们发现对于NOVA来说,仍有34%的时间花在VFS层上。ZoFS在用户空间部署文件系统,以避免陷入内核;然而,它仍然会带来额外的软件开销。ZoFS允许用户空间应用程序直接更新元数据,这可能导致正常程序在访问被恶意攻击者破坏的元数据时被终止。为了实现优雅的错误返回,ZoFS在每次系统调用开始时调用sigsetjump指令,这将导致额外的延迟(约200 ns)。SplitFS需要一个内核文件系统来处理元数据操作,所以它仍然会带来内核开销。
- 其他问题。首先,使用不当的指针可能导致写入错误的位置并损坏数据,这被称为偏离写入。Strata向用户空间应用程序公开每个进程的操作日志和DRAM缓存(包括元数据和数据)。Aerie和SplitFS映射文件系统映像的子集到用户空间。因此,偶然的写操作很容易破坏这些区域的数据,而且这种破坏在NVM中是永久的,即使是在重新引导之后。其次,Aerie、Strata和SplitFS通过延迟新写入数据到其他进程的可见性来提高性能,直到发出fsync,迫使应用程序做出相应的调整。第三,ZoFS严重依赖于MPK机制,如果应用程序也需要使用MPK,它们可能会竞争有限的MPK资源。
总而言之,现有的文件系统设计很难实现高可伸缩性和低软件开销,这促使我们引入Kuco架构。
3. Kuco架构
在这篇文章中,我们介绍了Kuco架构来说明一个客户/服务器模型可以被采用来同时实现这两个目标。Kuco的核心思想是客户端和服务器之间的细粒度任务分工和协作,大部分负载都被转移到客户端,以避免服务器成为瓶颈。
3.1 总览
图2显示了Kuco体系结构。它遵循客户机/服务器模型,其中包括两个部分,包括一个用户空间库和一个全局内核线程,这两个部分分别称为Ulib和Kfs。应用程序通过链接Ulib来访问Kuco,不同的Ulib实例(即应用程序)通过单独的内存消息缓冲区与Kfs交互。像现有的用户空间系统,Kuco映射PM空间到用户空间,以支持直接读写访问。为了保护文件系统元数据不被破坏,Kuco不允许应用程序直接更新元数据;相反,这些请求被发布到Kfs,然后Kfs代表它们更新元数据。
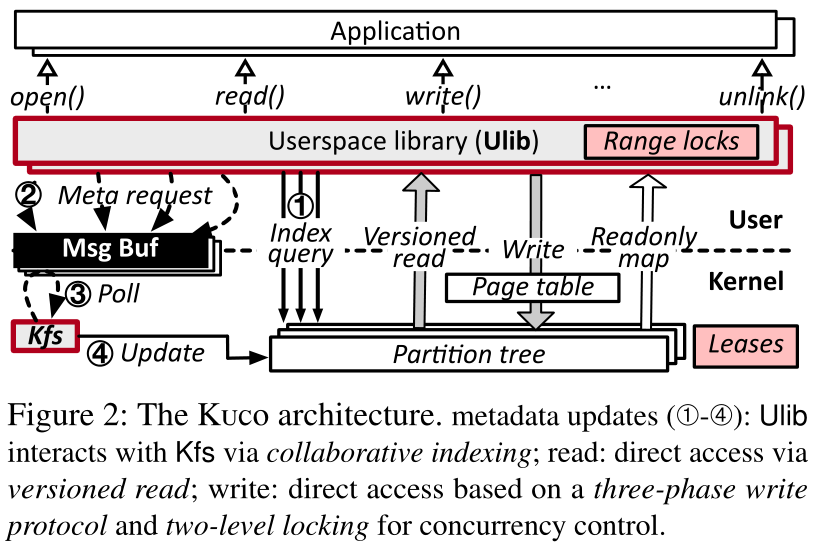
Kuco通过细粒度任务划分和Ulib与Kfs之间的协作提供了高可伸缩性。对于元数据的可伸缩性,Kuco整合了协作索引机制,将路径名遍历作业从Kfs卸载到用户空间(§3.2)。Ulib不会直接向Kfs发送元数据操作(如创建或解除链接),而是在用户空间中查找所有相关的元数据项,然后在发送请求之前将这些信息封装在请求中。因此,Kfs可以直接对给定的地址执行元数据修改。为了数据的可伸缩性,使用了两级锁机制来处理并发写入共享文件(§3.3)。具体来说,Kfs使用基于租赁的分布式锁来解决不同应用程序(或进程)之间的写冲突。来自同一个进程的并发写操作使用一个纯用户空间范围锁进行序列化,可以在不需要Kfs的情况下获取该锁。Kuco进一步引入了版本化的读取技术来执行用户空间中的文件读取(§3.5)。通过在数据块映射(将逻辑文件数据映射到物理PM地址)中添加额外的版本位,Kuco可以读取一致版本的数据块,而不需要与Kfs交互来获取锁,尽管还有其他并发写入器。
为了进一步防止有bug的程序破坏文件数据,PM空间以只读模式映射到用户空间。Kuco通过在内核中使用三相写协议(§3.4)将Kfs放置在只读地址上,从而允许用户空间直接写。在Ulib写文件之前,Kfs首先修改页表中的权限位,将相关的数据页从只读切换到可写。为了进一步减少编写文件时Ulib和Kfs之间的交互次数,Kuco采用了预分配(pre-allocation),这样Ulib可以从Kfs分配比预期更多的空闲页面。Kuco的PM空间除了有防止误写的写保护机制外,还被划分为不同的分区树,这些分区树作为读保护的最小单元。通过将Kuco应用于名为KucoFS的文件系统中,将所有技术结合在一起,获得了直接访问性能,提供了高可扩展性,并确保了内核级的数据保护。
3.2 协作索引
在典型的客户机-服务器模型中,每当Kfs收到元数据请求时,它都需要通过执行从根inode到包含该文件的目录的迭代路径名解析来查找相关的元数据(例如,描述文件属性的inode,或将文件名称映射到inode编号的dentries)。这种路径名遍历开销对Kfs来说是一个沉重的负担,特别是当目录包含大量子文件或具有很深的目录层次结构时。
为了解决这个问题,我们建议将路径名解析任务从Kfs转移到Ulib。通过将分区树映射到用户空间,Ulib可以直接在用户空间中找到相关的元数据项,然后通过在请求中封装元数据地址,向Kfs发送元数据更新请求。通过这种方式,Kfs可以直接用给定的地址更新元数据,并且路径名解析开销从Kfs转移到用户空间。
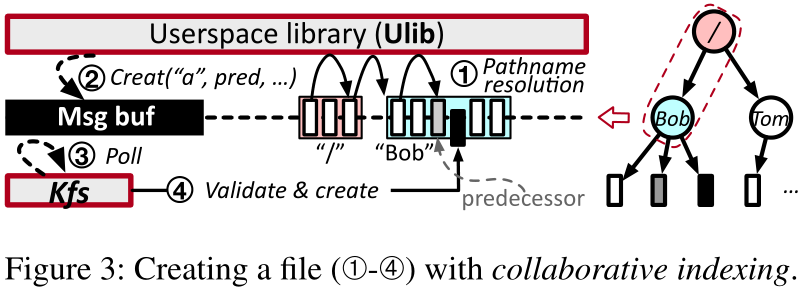
图3显示了Kuco如何创建一个路径名为“/Bob/a”的文件。Ulib首先在“Bob”(➀)的dentry列表中找到前任dentry文件“a”。然后它向Kfs发送一个创建请求,并且消息中也包含了前任的地址(➁)。Kfs在收到请求(➂➃)之后创建这个文件,其中包括为这个文件创建一个inode,然后在父目录的dentry列表中插入一个新的dentry,该dentry具有给定的前身。要删除一个文件,这个文件的inode和父目录中的dentry都应该被删除,所以在Ulib发送它之前,它们的地址都保存在unlink请求中。请注意,atime在默认情况下是禁用的,启用了在用户空间中执行只读操作(如stat、readdir),而不会向Kfs提交额外的请求。
在Kuco中,Ulibs生成指针,Kfs消耗它们。这种“单向”的指针共享范式简化了确保Kuco的正确性和安全性。一方面,元数据项被放置在一个有单独地址空间的元数据区域中,Ulib只能传递两种类型的元数据项的地址(即dentry和inode)。因此,我们在每个元数据项的开头添加一个标识符字段,这有助于Kfs检查元数据类型——任何不在元数据区域或没有指向dentry/inode的地址都被认为是无效的。另一方面,Kfs也基于文件系统内部逻辑执行一致性检查:
- 首先,Ulib可能读取不一致的目录树。例如,当Kfs在一个目录中创建新文件时,并发的Ulibs可能会读取该目录不一致的dentry列表。为了解决这个问题,我们用一个跳表来组织每个目录的dentry列表,每个dentry都由文件名的哈希值作为索引。跳表具有多层类似链表的数据结构。每个较高的层充当较低列表层的“快速通道”。基于列表的结构可以通过执行指针操作实现无锁的原子更新。此外,单个Kfs只对dentry列表执行插入和删除操作,包括重命名操作,重命名操作是通过先插入新节点,然后删除旧节点来执行的。因此,即使没有获取锁,对dentry的读也总是一致的。
- 其次,使用这种无锁设计,用户空间应用程序可能会读取Kfs正在删除的元数据项,从而导致“删后读”异常。为了安全回收已删除的项,我们需要确保不再有线程访问它。我们通过使用基于时代的回收机制来解决这个问题。EBR维护一个全局期和三个回收队列,其中执行被划分为多个时期,并在最后三个时期维护回收队列。每个线程还拥有一个私有的epoch。在epoch e中删除的项被放入到epoch e的队列中。每次Ulib启动操作时,它读取全局epoch,并更新自己的epoch,使其等于全局epoch。然后检查其他Ulib的私有epoch。如果所有的Ulibs在当前epoch e中都是活跃的,那么一个新的epoch开始了。此时,e或e+1中的所有线程都是活动的,与e-1相关的队列中的项目可以被安全回收。我们还在每个inode/dentry中添加了一个dirtyflag。Kfs通过将其dirtyflag设置为无效状态来删除元数据项,从而防止应用程序读取已经删除的项。
- 第三,Kfs需要正确处理冲突的元数据操作。例如,当多个Ulib同时执行元数据操作时,一个Ulib的预定位元数据项可能会在Kfs访问它之前被另一个并发的Ulib删除或重命名。因此,这个项目不再有效,它的地址不能再被Kfs使用。恶意进程也可能通过提供任意地址来攻击Kfs。幸运的是,只有Kfs可以更新元数据,并且它可以在处理操作之前验证预先定位的元数据。具体来说,Kfs检查预先定位的项是否仍然存在或仍然是前任,并避免创建同名的文件。当验证失败时,Kfs将解析路径名本身,并在操作失败时向Ulib返回一个错误代码。
讨论。首先,Kuco确保所有元数据操作都是原子处理的。对于create, Kfs只有在创建了一个inode之后才会在跳跃列表中插入一个新的dentry,以使被创建的文件可见;对于unlink,它会在删除其他字段之前自动删除dentry。重命名涉及更新两个dentry(在目标路径中创建一个新条目,然后删除旧条目),因此程序可以在某个时间点在两个位置上看到两个相同的文件。我们在每个dentry中利用dirtyflag来防止这种不一致的状态。具体来说,源路径上的旧条目在创建新条目之前被设置为dirty,然后在创建新条目之后被设置为无效。作为一个整体,我们可以观察到元数据操作总是自动地改变目录树,即使不获取锁,Ulib也可以保证具有一致的目录树视图。其次,通过避免使用锁,Kuco的可伸缩性得到了进一步的提高——并发元数据更新都被委托给全局Kfs,因此它们可以在没有任何锁开销的情况下被处理(只有Kfs可以更新元数据)。Kuco通过操作日志确保元数据崩溃的一致性,这将在§4.2中讨论。
3.3 两级锁
Kuco引入了一个两级锁服务来协调对共享文件的并发写操作,这就避免了Kfs频繁地参与并发控制。首先,Kfs分配文件的写租期(在内核中,参见图2)来强制不同进程之间的粗粒度协调,类似Aerie和Strata。只有持有有效的写租约(尚未过期)的进程才能写该文件。我们假设Ulib很少申请租约,这是基于这样一个事实,即多个进程频繁地并发地写同一个文件并不常见。可以通过共享内存或管道实现进程间更细粒度的共享。在Kuco不需要读租(见章节3.5)。
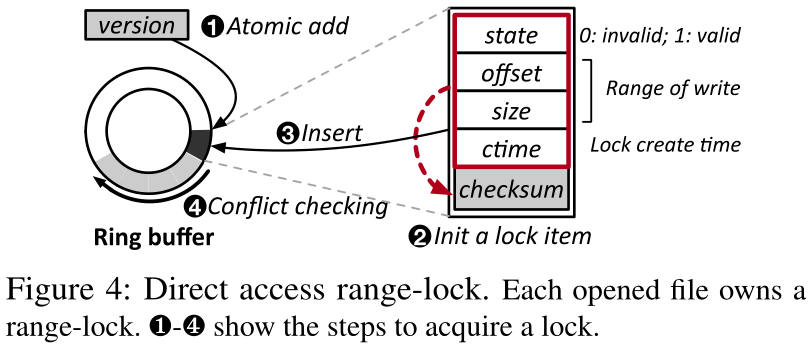
其次,我们引入了一个直接访问范围锁来序列化同一进程中线程之间的并发写操作。一旦Ulib获得了文件的写租期,它就会在用户空间中为这个文件创建一个范围锁,这实际上是一个DRAM环缓冲区(如图4所示)。线程通过首先获取范围锁来写入文件,如果发生锁冲突,它就会被阻塞。环形缓冲区中的每个槽都有五个字段,分别是state、offset、size、ctime和checksum。校验和是前四个字段的哈希值。我们还在每个循环缓冲区的头部放置一个版本,以描述每个写操作的顺序。为了获得文件的锁,ulib首先使用原子的fetch_and_add来增加版本(①)。然后,它将一个锁项插入到环缓冲区的特定槽位中(②和③,这个位置由获取的版本号对环缓冲区大小取模确定)。当这个插槽与环形缓冲区的头部重叠时,插入被阻塞。在此之后,Ulib向后遍历循环缓冲区,以找到第一个冲突的锁项(即它们的写入数据重叠)。如果存在这样的冲突,Ulib会验证它的校验和,然后对它的状态进行轮询,直到它被释放(④)。如果线程在释放锁之前中止,Ulib还会反复检查它的ctime字段,以避免死锁。通过这种设计,多个线程可以在同一个文件中并发地写入不同的数据页。
3.4 三相写
一旦锁已经被获得,Ulib就可以实际写入文件数据。因为PM空间以只读模式映射到用户空间,所以Ulib不能直接写文件数据。相反,我们提出了一个三相写协议来执行直接写。为了确保崩溃的一致性,Kuco采用了copy-on-write (CoW)方法来写文件数据,其中新写入的数据总是重定向到新的PM页面。与NOVA和PMFS]类似,我们使用4KB作为默认的数据页面大小。Kuco中的写协议包括三个步骤。首先,Ulib通过两级锁定锁定文件,并向Kfs发送请求来分配新的PM页面。注意,通过使用CoW方式,覆盖和追加操作都需要空间分配。Kfs还需要修改相关的页表条目,以便在返回响应消息之前使这些分配的PM页面可写。其次,Ulib将未修改的数据从旧位置复制到用户缓冲区,并将新数据复制到已分配的PM页面,并通过flush指令将它们持久化。第三,Ulib向Kfs发送另一个请求来更新这个文件的元数据(即inode、块映射),将新写的页面切换为只读,最后释放锁。
此外,我们引入了预分配机制,以避免为每个写操作从Kfs分配新的PM页。具体来说,我们允许Ulib从Kfs分配比预期更多的空闲页面(在我们的实现中,每次分配4 MB)。通过这种方式,Ulib可以使用本地空闲PM页面,而不需要与Kfs进行大多数写操作。当应用程序退出时,将未使用的页面返回给Kfs。对于异常退出,这些空闲页面暂时不能被其他应用程序重用,但仍然可以在恢复阶段回收(见§4.2)。预分配还有助于减少更新页表项的开销。当Kfs在每次分配后更新页表项时,它需要显式刷新相关的TLB项,以使修改可见。预分配允许一次分配多个数据页,因此TLB条目可以批量刷新。
3.5 版本化读取
在写协议中,由于CoW方式,新旧版本的数据页都被临时保留,这为我们提供了在不阻塞写操作的情况下读取数据的机会。但是,将逻辑文件映射到物理页面的块映射仍然由Kfs及时更新。这促使我们设计版本化的读机制来实现用户级的直接读,而不需要任何Kfs的参与,不管并发的写程序是什么。
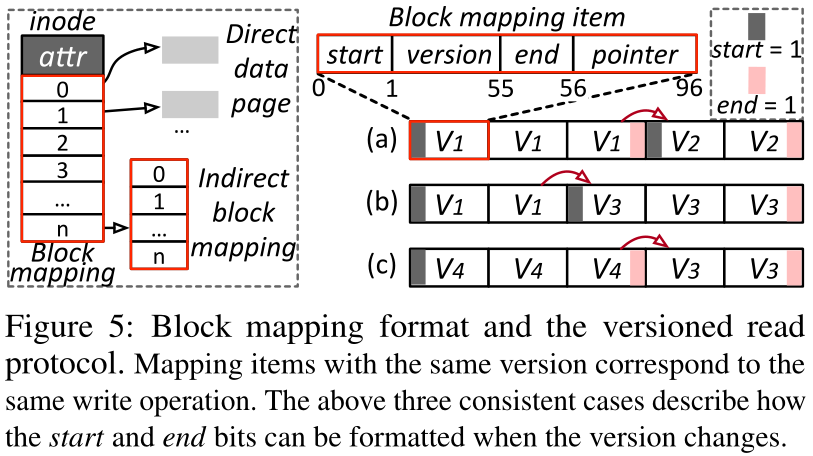
版本化读取的设计目的是允许用户空间读取而不锁定文件,同时确保读取者不会从不完整的写入中读取数据。为了实现这一点,Kuco使用了一个类似于ext2的块映射来索引数据页,并在块映射的每个指针中嵌入一个版本字段。如图5所示,每个96位块映射项包含四个字段,分别是start、version、end和pointer。对于写操作,例如写3个数据页,Kfs按照如下格式更新对应的块映射项:1|V1|0|P1,0|V1|0|P2,0|V1|1|P3。特别是,这三个项目共享同一个版本(即V1),这是由Ulib在获取范围锁时提供的(在3.3节中)。第一项的起始位和最后一项的结束位设置为1。我们只为指针字段保留40位,因为它指向一个4kb对齐的页面,较低的12位可以丢弃。
在这种格式下,当遇到图5中的三种情况之一时,读取器可以读取一致的数据页快照:
- a) 没有重叠。当在不重叠的页面上对文件执行两次更新时,具有相同版本的项目应该同时包含一个开始位和一个结束位(在情况a中是V1和V2)。
- b) 重叠结束部分。当线程重写前一个写的结束部分时,当版本增加时,读取器应该总是看到一个开始位(V1➔V3)。
- c) 与前面部分重叠。当一个线程重写前一个写的前半部分时,读取器应该总是在版本下降之前看到一个结束位(V4➔V3)。
如果Ulib满足上述三种情况之外的任何情况,则表明Kfs正在更新一些其他未完成写操作的块映射。在这种情况下,Ulib需要通过重新扫描相关版本的序列再次验证。在Ulib成功进行版本检查后,它然后读取相关的数据页。总的来说,Kuco利用嵌入式版本来检测不完整的写操作和重试操作,直到读取一致的数据快照。
读语义。在多线程/进程执行中,版本化读与传统锁定读略有不同,因为它允许并发写。例如,一个写操作已经开始,但还没有完成,但是在这中间,有一个读操作,读取数据的一个旧快照。在本例中,执行仍然等于一个可序列化的顺序(例如,“read➛write”,“➛”表示happens-before)。在每个线程中,版本化读与锁定读具有相同的语义,因为一个读或写必须在发出下一个读或写之前完成。
4. KucoFS实现
在本节中,我们将描述如何在名为KucoFS的持久内存文件系统中应用Kuco架构。
4.1 数据布局
KucoFS使用DRAM和PM的混合方式来组织Kuco的分区树(图6)。在DRAM中,一个指针数组(inode表)被放置在一个预定义的位置,以指向实际的inode。inode表中的第一个元素指向当前分区树的根inode。这样,Ulib就可以从用户空间的根节点查找任何文件。如前所述,目录的dentry列表被组织成一个跳跃列表,它也被放置在DRAM中。
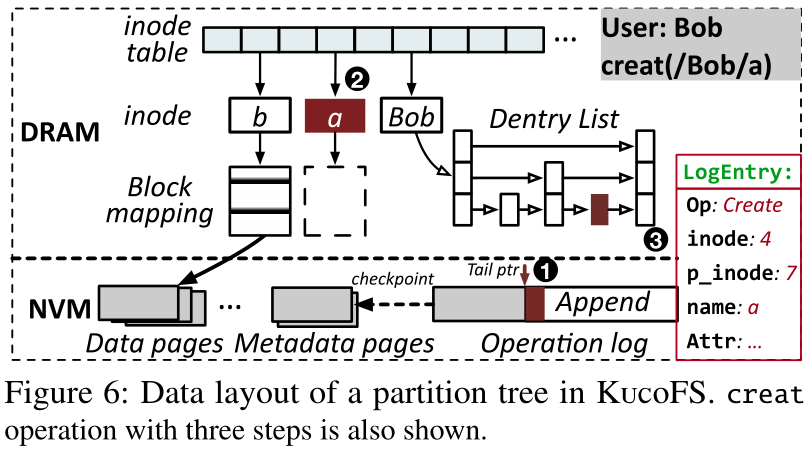
为了提高效率,KucoFS仅在正常请求时对DRAM元数据进行操作。为了确保元数据的持久性和崩溃一致性,KucoFS在PM中为每个分区树放置了一个仅追加的持久操作日志。当Kfs更新元数据时,它首先自动附加一个日志条目,然后实际更新DRAM元数据(见§4.2)。当系统发生故障时,可以通过重放操作日志中的日志项来恢复DRAM元数据。除了操作日志之外,额外的PM空间被分割成4KB的数据页和元数据页。空闲PM页面使用PM中的位图和DRAM中的空闲列表来管理(用于快速分配),并且位图在检查点阶段由Kfs延迟持久化。
4.2 崩溃一致性及恢复
元数据的一致性。KucoFS通过命令更新DRAM和PM来确保元数据的一致性。图6显示了Kfs在从Ulib接收到创建请求时如何创建文件的步骤。在➊处,Kfs从inode表中保留了一个未使用的inode号,并在操作日志中添加了一个日志项。这个日志条目记录了inode号、文件名、父目录inode号和其他属性。在➋中,它分配一个每个字段都被填充的inode,并更新inode表以指向这个inode。在➌中,它然后将一个dentry插入到dentry列表中,该dentry具有前任的给定地址,以使被创建的文件可见。如果同一个dentry已经存在,则创建失败(避免创建相同的文件)。要删除一个文件,Kfs首先添加一个日志条目,删除父目录中具有给定地址的dentry,最后释放相关空间(如inode、数据页和块映射)。如果在操作完成之前发生了崩溃,那么DRAM元数据更新将丢失,但是Kfs可以在恢复之后通过重放日志来将它们重构到最新的状态。对于重命名操作,除了系统故障外,内核线程可能会崩溃,并导致dirtyflag处于不一致的状态。但是,如果内核线程崩溃,我们会考虑整个文件系统崩溃,这需要重新引导文件系统,并且上面的日志技术确保重命名操作也与崩溃保持一致。
数据一致性。KucoFS处理文件的写操作时,首先以CoW的方式更新数据页面,然后在操作日志中附加一个日志条目,记录元数据的修改。此时,写操作被认为是持久的。然后,KucoFS可以安全地更新DRAM元数据,使此操作可见。当在日志条目被持久化之前发生系统故障时,KucoFS可以回滚到它的最后一个一致状态,因为旧的数据和元数据不会被修改。否则,这个写操作在恢复后通过重放操作日志可见。
日志清理和恢复。我们引入了检查点机制,以避免操作日志任意增长。当Kfs不繁忙或日志大小超过阈值(在我们的实现中为1MB)时,我们使用一个后台内核线程来触发一个检查点,该检查点将操作日志中的元数据修改应用到PM元数据页面。用于管理PM空闲页面的位图也被更新和持久化。之后,操作日志被截断。后台消化不会阻塞前端操作,唯一的影响是日志清理会消耗额外的PM带宽。然而,元数据通常规模较小,带宽消耗也不高。
每次KucoFS从崩溃中重新启动时,Kfs首先会在操作日志中重放未检查的日志条目,以便使PM元数据页面更新。然后它将PM元数据页复制到DRAM。根据存储在PM中的位图重新构建PM数据页的空闲列表。不需要担心在恢复期间再次崩溃,因为日志还没有被截断,可以再次播放。在DRAM和PM之间保持元数据的冗余副本会增加PM/DRAM空间的消耗,但我们认为这是值得的。有了DRAM中的结构化元数据,我们可以直接在DRAM中执行快速索引;在日志中追加日志条目可以节省更新pm的次数,从而减少了持久性开销。今后,我们计划通过只在DRAM中保留活动元数据来减少DRAM的占用空间。
4.3 写保护
KucoFS严格控制对文件系统镜像的更新。内存中的元数据和持久操作日志都是关键的,因此内核中的Kfs是唯一允许更新它们的。文件页以只读模式映射到用户空间。应用程序只能将数据写入新分配的PM页面,而不能修改现有的数据页面。KucoFS还为用户空间数据结构提供进程级隔离。消息缓冲区和范围锁是每个进程私有的,因此攻击者无法在其他进程中访问它们,除非它执行特权升级攻击。这些安全问题超出了本工作的范围。因此,我们认为KucoFS实现了与内核文件系统相同的写保护。
防止偏离写。与许多现有的用户空间文件系统不同,一些PM文件系统容易受到偏离写的攻击,KucoFS通过将PM空间映射为只读模式来防止这个问题。请注意,在写操作完成后,在权限位改变之前,仍然有一个临时的可写窗口(小于1µs)用于新写的页面。这是不可避免的,就像在现有的内核文件系统(如PMFS)中一样。幸运的是,这种情况很少发生。此外,用户空间中的范围锁和消息缓冲区也可能被偏离写操作破坏。对于这个威胁,我们在每个槽上添加checksum和租约字段,它们可用于检查插入的元素是否被破坏。
4.4 读保护
KucoFS用分区树组织目录树,分区树充当访问控制的最小单元。每个分区树都是自包含的,包括PM中的元数据和数据,以及DRAM中的相关元数据拷贝。KucoFS不允许文件/目录结构跨不同的分区。当一个程序访问KucoFS时,只有它可以访问的分区树被映射到它的地址空间,但是其他的分区树对它是不可见的。
在KucoFS中,通过以下妥协加强了读访问控制。首先,类似于现有的用户空间文件系统,KucoFS不支持“只写”或复杂的权限语义,如POSIX访问控制列表(acl),因为现有的页表只有一个位来表示页面是只读或读写的。其次,KucoFS不支持用户之间灵活的数据共享,因为使用分区树设计很难改变特定文件的权限(例如,通过chmod)。但是有几种实用的方法:① 创建一个独立的分区,让具有不同权限的应用程序可以访问它;② 在不同应用之间下发用户级rpc获取数据。我们认为这种权衡不太可能成为障碍,因为KucoFS仍然支持同一个用户内的应用程序之间的高效数据共享,这是现实世界中场景中更常见的情况。
4.5 内存映射I/O
在“写时复制”系统中支持DAX特性需要额外的努力,因为在正常的写操作中更新文件的位置不对。此外,DAX为程序员正确使用具有原子性和崩溃一致性的PM空间带来了巨大的挑战。考虑到这些因素,我们借用了NOVA的想法来提供原子mmap,它有更高的一致性保证。当应用程序将文件映射到用户空间时,Ulib将文件数据复制到其私有管理的数据页面,然后向Kfs发送请求,将这些页面映射到连续地址空间。当应用程序发出一个msync系统调用时,Ulib就会把它作为一个写操作来处理,这样就可以原子地使这些数据页面中的更新对其他应用程序可见。
4.6 KucoFS的API
KucoFS提供了一个类posix的接口,因此现有的应用程序可以在不修改源代码的情况下访问它。我们通过设置LD_PRELOAD环境变量来实现这一点。Ulib拦截标准C库中所有与文件系统操作相关的api。如果访问文件的前缀与预定义的字符串(例如/kuco/usr1)匹配,则Ulib直接处理系统调用。否则,系统调用将以旧模式处理。注意,读或写操作只传递在参数列表中的文件描述符。Ulib通过一个映射表将它们与旧的系统调用区分开来,该映射表跟踪KucoFS的文件。
4.7 例子:将它们全部放在一起
最后,我们通过一个将4kb的数据写入一个新文件,然后将其读取出来的例子来总结Kuco架构和KucoFS的设计。
Open。在发送打开文件的请求之前,Ulib首先预先定位相关的元数据。因为这是一个新文件,所以Ulib不能直接找到它。相反,它会在父目录的dentry列表中找到前身,以便以后创建。地址,以及其他信息(例如,文件名,O_CREAT flags,等等)都封装在开放请求中。当Kfs接收到请求时,它会根据给定的地址创建这个文件。它还需要为这个进程分配写租约。然后,Kfs发送一条响应消息。在此之后,Ulib为这个打开的文件创建一个文件描述符和一个范围锁,并返回到应用程序。
Write。然后,应用程序通过Ulib使用写调用将4KB的数据写入这个新创建的文件。首先,Ulib试图通过两阶段锁定服务锁定文件。因为写租约仍然有效,所以它直接通过范围锁来获取锁。当出现写冲突时,Ulib阻塞程序,并等待其他并发线程释放锁。在此之后,Ulib可以成功地获取锁。然后,它从预分配的页面中分配一个4 kb的页面,将数据复制到其中,并将它们从CPU缓存中刷新出来。一旦预分配的空间用完,Ulib还需要向Kfs发出一个额外的请求来分配更多的空闲数据页。最后,Ulib将写请求发送给Kfs以完成其余步骤,包括将已写数据页的权限位更改为只读,附加一个日志条目来描述此写操作,以及更新DRAM元数据。Ulib最后解锁范围锁中的文件。
Read。KucoFS可以在不与Kfs交互的情况下读取文件数据。要从这个文件中读取前4KB, Ulib寻找用户空间中的inode并读取第一个块映射项。执行版本检查以确保其状态满足3.5节中描述的三个条件之一。在此之后,Ulib可以安全地读取映射项中的指针所指向的数据页。
Close。在关闭这个文件时,Ulib还需要向Kfs发送一个关闭请求。Kfs然后收回写租约,因为它不再访问这个文件了。
5. 实验评估
在我们的评估中,我们试图回答以下问题:
- KucoFS是否实现了提供直接访问性能和高可伸缩性的目标?
- KucoFS中的每一项技术是如何帮助实现上述目标的?
- KucoFS在宏观基准测试和实际应用中表现如何?
5.1 实验设置
实验台。我们的实验台配备了2个Intel Xeon Gold 6240M cpu(36个物理核),384GB DDR4 DRAM, 12个Optane DCPMM(每个模块256GB,共3TB)。我们在NUMA 0 (1.5 TB)上的Optane DCPMM上进行了所有的实验,其读带宽峰值为37.6 GB/s,写带宽为13.2 GB/s。服务器上安装了Ubuntu 19.04和Linux 5.1,这是NOVA支持的最新内核版本。
比较系统。我们将KucoFS与NVM感知文件系统(包括PMFS、NOVA、SplitFS、Aerie和Strata)以及支持DAX的传统文件系统(包括Ext4-DAX和XFS-DAX)进行比较。Strata只支持少数应用程序,运行多线程工作负载有困难。与之前的文献相似,在§5.3和§5.4中只给出了部分性能结果。我们只在§5.2和§5.4中评估SplitFS,因为它只支持API的一个子集。为了进行比较,我们使用严格模式部署SplitFS,这确保了持久性和原子性。ZoFS不是开源的,所以我们没有评估它。Aerie基于Linux 3.2.2,不支持Optane DCPMM。因此,我们通过使用DRAM模拟持久内存来与Aerie进行比较,它会注入额外的延迟。由于篇幅有限,我们只口头描述了Aerie的实验数据,没有添加额外的数字。
5.2 独立技术的影响
我们使用FxMark来分析各个技术的影响,探索基本文件系统操作的可伸缩性。FxMark提供了19个微基准,根据4个标准进行分类:数据类型(即数据或元数据)、模式(即读或写)、操作和共享级别。由于篇幅有限,我们只对常用的操作(如读、写、mknod等)进行评估。
5.2.1 协同索引的影响
基本性能。在KucoFS中,创建操作需要向Kfs发布请求,所以我们选择这个操作来显示协作索引的效果。FxMark通过让每个客户端线程在私有目录(即低共享级别)或共享目录(即中共享级别)中创建10个kfile来评估创建操作。如图7a和7b所示,在比较的文件系统中,KucoFS表现出最高的性能,而且无论共享级别如何,它的吞吐量都不会崩溃。XFS-DAX、Ext4-DAX和PMFS使用全局锁在共享日志中执行元数据日志记录,这导致它们的可伸缩性很差。NOVA通过避免全局锁(例如,它使用每个inode日志并对其空闲空间进行分区),在低共享级别下显示了出色的可伸缩性。然而,所有的内核文件系统都不能在中共享级别下扩展,因为VFS需要在创建文件之前锁定父目录。SplitFS依赖于Ext4来创建文件,这导致了它的可伸缩性很低。从ZoFS的论文中我们还发现,在低共享级别下,ZoFS甚至显示出比NOVA更低的吞吐量,因为它需要频繁地进入内核来分配新的空间。Aerie支持通过批处理(通过降低可视性)将创建文件的元数据更新同步到TFS,因此它可以实现与KucoFS相当的性能。当线程数增加时,Aerie无法正常工作。而KucoFS的吞吐率仅随介质共享级别的提高而略有下降,其吞吐率比其他文件系统高一个数量级,比ZoFS高3倍。我们从以下几个方面来解释KucoFS的高可扩展性。首先,在KucoFS中,所有元数据更新都被委托给Kfs,因此Kfs可以在没有任何锁定开销的情况下更新它们。其次,通过将索引任务转移到用户空间,Kfs只需要执行轻量级工作。
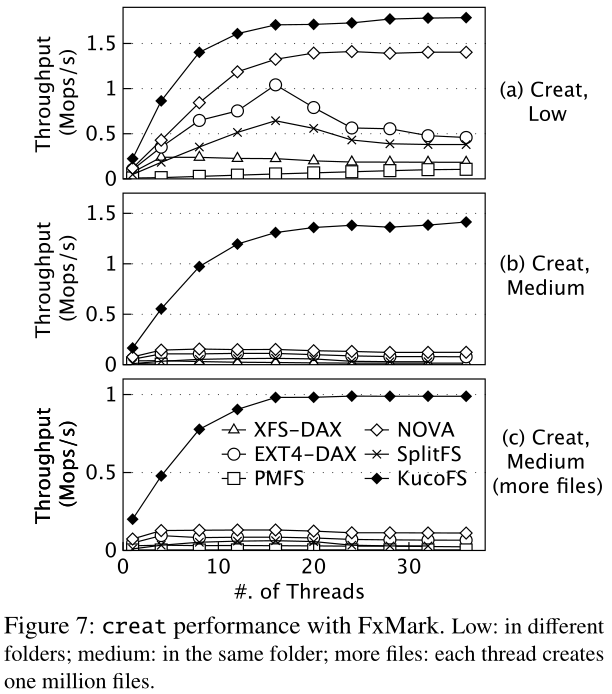
更大的工作负载。此外,我们通过扩展工作负载大小来衡量KucoFS在数据容量方面的可伸缩性。具体来说,我们让每个线程创建100万个文件,比FxMark中的默认大小大100倍,结果如图7c所示。与工作负载较小的结果相比,KucoFS的吞吐量下降了28.5%。这主要是因为当文件数量增加时,文件系统需要更多的时间在父目录中找到合适的插入槽。即便如此,KucoFS仍然比其他文件系统的性能好一个数量级。
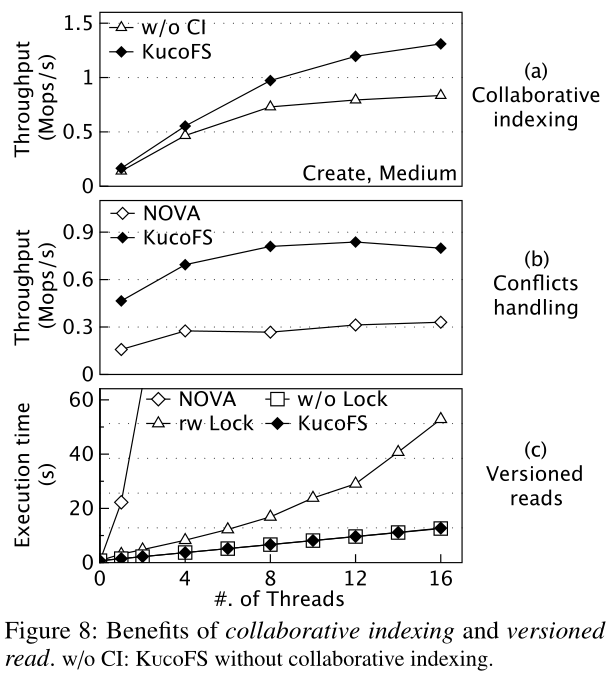
冲突处理。当发生冲突时,KucoFS要求Kfs退回并重试,这可能会影响整体性能。在这方面,我们还测试了KucoFS在处理相互冲突的操作时的行为。具体来说,如果同一个文件不存在,我们使用多个线程并发地创建它,或者在它已经创建时删除它。我们收集这些成功创建和删除的吞吐量,结果如图8b所示。作为对比,NOVA的结果也显示在图中。我们可以看到,KucoFS的吞吐量比NOVA高2.4倍。在NOVA中,线程需要在创建或删除文件之前获取锁。更糟糕的是,如果创建或删除失败,其他并发线程将被不必要地阻塞,因为锁不能保护有效的操作。相反,在KucoFS中,线程可以向Kfs发送创建或删除请求,而不会被阻塞,Kfs负责确定这个操作是否可以成功处理。此外,由于Ulib已经在请求中提供了相关的地址,Kfs可以直接使用这些地址来验证元数据项,这带来的开销并不大。
崩溃。我们还通过与禁用此优化的KucoFS的一种变体(即,将元数据索引任务移回Kfs,表示为“w/o CI”)进行比较,来衡量协同索引的好处。图8a显示了使用不同数量的客户机测量create吞吐量的结果。我们作出以下观察。首先,在单线程评估中,协作索引并不有助于提高性能,因为将元数据索引任务从Ulib移回Kfs并不能减少每个操作的总体延迟。其次,当客户端线程数量增加时,我们发现协作索引可以将吞吐量提高55%。由于KucoFS只允许Kfs代表多个Ulib实例更新元数据,理论上的吞吐量限制是Tmax = 1/L (Ops/s,其中L是Kfs处理一个请求的延迟)。因此,卸载机制通过缩短每个请求的执行时间(即L)来提高性能。
5.2.2 版本化读取的影响
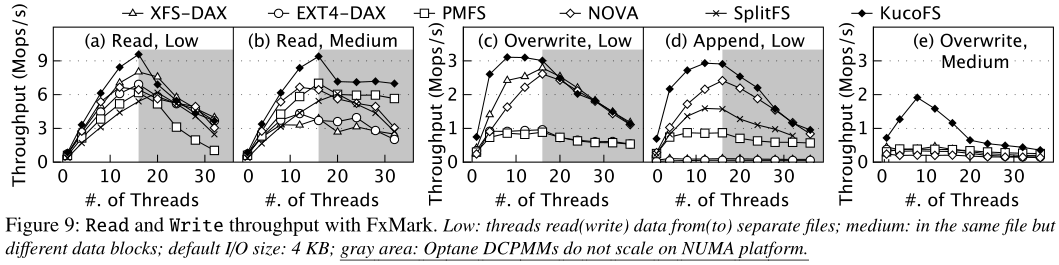
图9a和图9b显示了在不同的共享级别(即低/中)下,不同线程数的每个文件系统的文件读性能。我们作出以下观察。首先,在比较的文件系统中,KucoFS的吞吐量最高,最高达到9.4 Mops/s(硬件带宽已经充分利用)。性能改进主要来自版本化读的设计,它允许用户空间直接访问,而不需要Kfs的参与。这些内核文件系统(例如,XFS、Ext4、NOVA和PMFS)必须执行上下文切换和遍历VFS层,这会影响读性能。尽管SplitFS具有直接访问特性,但其性能只能与NOVA相媲美。我们发现,每当SplitFS读取尚未被映射的页面时,它都需要将更多的PM空间映射到用户空间,这将导致额外的开销。对于介质共享级别,KucoFS的性能提升更为明显,因为所有比较的系统都需要在实际读取文件数据之前锁定文件。尽管它们使用了共享锁,但锁定开销会显著影响它们的性能。第二,当线程数不断增加时,所有已评估文件系统的读性能都会急剧下降(灰色区域)。为了获得稳定的结果,我们首先将线程绑定到NUMA 0(本地访问),只有当线程总数大于18时,NUMA 1的内核才会被使用。我们和过去的工作都观察到,跨套接字访问Optane会极大地影响性能。为了确认我们的软件设计是可伸缩的,我们在DRAM中部署了NOVA和KucoFS,它们都再次显示了可伸缩的读吞吐量。因此,最近的许多论文在评价时仅使用了本地NUMA节点的核。在我们的模拟持久化内存中,Aerie在低共享级别下的性能与KucoFS几乎相同,但在中共享级别下,由于Aerie需要频繁与TFS交互,其吞吐量远远落后于其他KucoFS。
我们进一步演示了通过并发地从/向同一文件读取/写入数据来实现版本化读取的效果。在我们的计算中,选择一个读线程顺序地读取I/O大小为16KB的文件,然后启动越来越多的线程并发地覆盖相同的文件(将4KB写入一个随机偏移量)。我们让读线程发布读操作100万次,并使用不同数量的写入器来度量它的执行时间。为了比较,我们还实现了KucoFS r/w锁,通过在范围锁环缓冲区中获取读写锁来读取文件数据,以及KucoFS w/o锁,它直接读取文件数据,而没有正确性保证。我们从图8b中观察到以下情况。首先,所提出的版本化读实现了与KucoFS w/o锁几乎相同的性能。这证明版本检查的开销非常低。我们还观察到,KucoFS r/w锁需要更多的时间来完成读取(在不同的I/O大小下,比KucoFS多7%到3.2倍的时间)。这是因为它需要使用原子操作来获取范围锁,当冲突频繁时,这会严重影响读性能。第二,NOVA的执行时间比KucoFS的执行时间高几个数量级。NOVA直接使用互斥体来同步读取器和并发写入器。因此,读者总是被作者阻塞。
5.2.3 三相写的影响
我们评估追加和覆盖操作来分析写协议(见图9 c-d)。对于共享级别较低的覆盖操作,一些覆盖操作呈现先增加后降低的性能曲线。在上升部分,KucoFS在比较系统中显示出最高的吞吐量,因为它可以直接向用户空间写入数据。XFS和NOVA也显示了良好的可伸缩性。其中,NOVA分区空闲空间,以避免分配新数据页时的锁定开销,而XFS直接就地写入数据,而不分配新页面。PMFS和Ext4都无法扩展,因为它们依赖于一个集中的事务管理器来写入数据,从而引入了额外的锁定开销。在下降的部分,它们的吞吐量主要受到两个因素的影响:跨numa开销,这已经在前面解释过了,以及Optane的写性能的可伸缩性差。在此设置下,SplitFS无法正常运行。对于追加操作,随着线程数量的增加,XFS-DAX、Ext4DAX和PMFS表现出较差的可伸缩性。这是因为它们使用全局锁来管理空闲数据页和元数据日志,所以锁争用会增加主要的开销。NOVA和KucoFS都表现出了更好的可扩展性,随着线程数的增加,KucoFS的性能比NOVA高出10%到2倍。SplitFS的吞吐量介于NOVA和Ext4-DAX之间。这是因为,SplitFS首先在暂存文件中追加数据,然后通过捕获到内核将其重新链接到原始文件。在我们的模拟持久内存中,Aerie的性能最差,因为可信服务是瓶颈,客户端需要频繁地与TFS交互来获取锁和分配空间。
两级锁定。为了分析锁设计的影响,我们还评估了介质共享级别的覆盖操作,其中线程以不同的偏移量将数据写入同一个文件。如图9e所示,当线程数较小时,KucoFS的吞吐量比其他四个文件系统高出一个数量级(在此设置下,SplitFS无法正常运行)。KucoFS中的范围锁设计允许对同一文件中的不同数据块进行并行更新。当线程数增加到8以上时,KucoFS的性能再次下降,这主要是受到范围锁(range-lock)中的环缓冲区大小的限制(我们在环缓冲区中保留8个锁槽)。我们还发现ZoFS的吞吐量比NOVA高2-3倍(他们的论文中的图7f),但它仍然不如KucoFS。
内存映射I/O。内存映射I/O是访问文件系统的最有效方式。KucoFS中的Kfs在处理mmap请求时,会提前构造所有的页表。为了进行比较,我们在使用mmap访问内核文件系统时添加了MAP_POPULATEflag,它在系统调用期间构建页表。实验结果如预期的那样(没有在图中显示):当我们并发发出4KB的读/写请求时,所有评估的文件系统都使硬件带宽饱和。
5.3 Filebench:宏基准测试
然后,我们使用Filebench作为一个宏基准来评估KucoFS的性能。表2显示了两种工作负载设置(与NOVA论文中的设置类似)以及使用1和16个线程的实验结果(使用Filebench增加更多线程不会提高吞吐量)。我们可以看到,首先,在所有评估的工作负载中,KucoFS的性能最高。在使用Fileserver工作负载进行单线程评估时,其吞吐量分别比XFS、Ext4、PMFS、NOVA和Strata高2.5×、1.9×、1.38×、1.39×和1.32×,比Varmail工作负载高3.2×、5.6×、1.9×、1.45×和1.13×。对于以读为主的工作负载(例如,webserver/webproxy),KucoFS还显示出略高的吞吐量。性能的提升主要来自于KucoFS的直接访问特性。Strata也受益于直接访问,并在大多数工作负载中表现第二好。我们还观察到,KucoFS的设计非常适合Varmail工作负载。这是预期的:Varmail经常创建和删除文件,因此它会产生更多的元数据操作,并更频繁地发出系统调用。如前所述,KucoFS消除了操作系统部分的开销,并且更擅长处理元数据操作。此外,Strata比NOVA显示出更高的吞吐量,因为Varmail中的文件I/O很小。Strata只需要在操作日志中追加这些小的更新,大大减少了写放大。
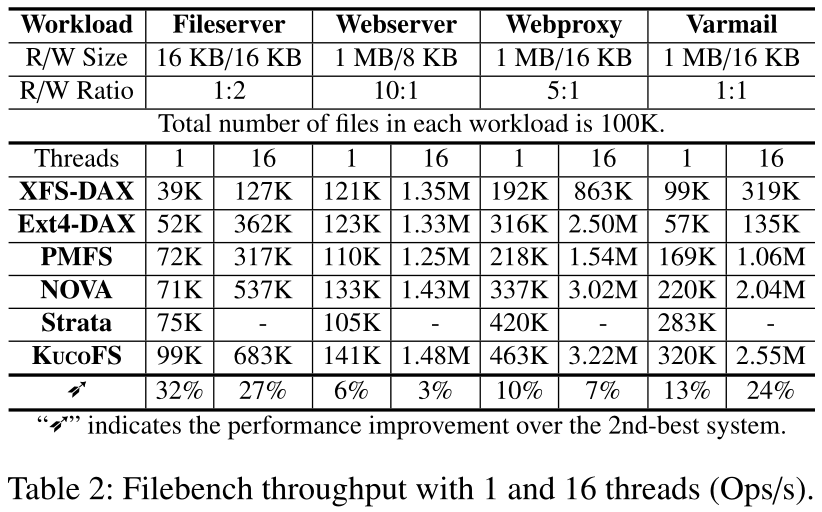
其次,KucoFS在处理并发工作负载方面做得更好。在Fileserver工作负载下有16个客户端线程,KucoFS的性能比XFS-DAX好4.4倍,比PMFS好1.2倍,比NOVA好27%。对于Varmail工作负载,性能提升更为明显:它的平均性能比XFS-DAX和Ext4-DAX高10倍。有两个原因促成了它的良好性能:首先,KucoFS结合了协作索引等技术,使Kfs能够提供可伸缩的元数据访问性能;其次,KucoFS通过让每个客户端管理私有的自由数据页面来避免使用全局锁。NOVA还展示了良好的可伸缩性,因为它使用每个inode的日志结构,并对空闲空间进行分区,以避免全局锁。
5.4 Redis:现实应用程序
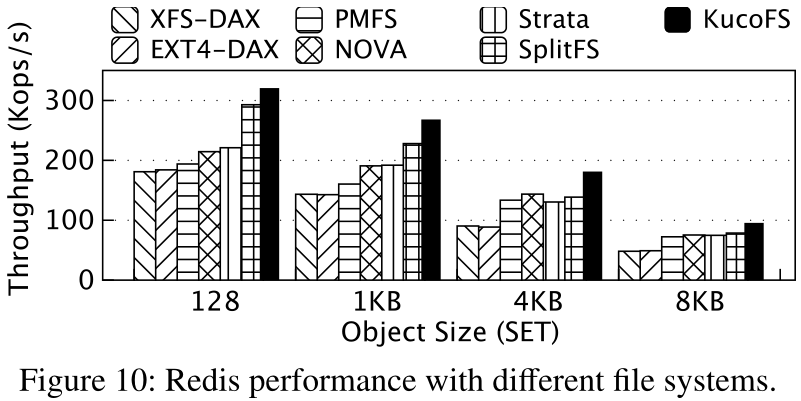
Redis导出了一组api,允许应用程序处理和查询结构化数据,并使用文件系统进行持久的数据存储。Redis有两种方法来持久地记录数据:一种是将操作记录到仅追加文件(AOF)中,另一种是使用异步快照机制。本文仅用AOF模式对Redis进行评估。图10显示了使用不同值大小的12字节键的SET操作的吞吐量。对于小值,Redis在KucoFS上的吞吐量平均比PMFS、NOVA和Strata高53%,比XFS-DAX和Ext4-DAX高76%。这与5.2节中append的结果一致。由于对象大小较大,KucoFS的吞吐量比其他文件系统略高,因为大部分时间都花在写数据上。请注意,Redis是一个单线程应用程序,因此KucoFS在8KB对象(约800MB/s)下实现100 Kops/s的吞吐量是合理的。SplitFS很擅长处理追加操作,因为它在用户空间中处理数据平面操作。然而,它的性能仍然不如KucoFS,因为Redis每次添加新数据时都会发布fsync来刷新AOFfile。因此,SplitFS需要捕获到内核中来更新元数据,这再次导致了VFS和系统调用开销。
6. 相关工作
内核-用户空间协作。将I/O操作从内核移动到用户空间的想法已经得到了很好的研究。Belay等人的Dune利用现代处理器中的虚拟化硬件抽象出Dune进程。它允许直接访问用户空间中的特权CPU指令,并以减少开销的方式执行系统调用。在Dune的基础上,IX进一步提高了数据中心应用程序的性能,将内核(控制平面)的管理和调度功能与网络处理(数据平面)分离开来。Arrakis是一种新的网络服务器操作系统,应用程序可以直接访问I/O设备,内核只执行粗粒度保护。FLEX通过将传统的文件操作替换为类似的基于DAX的操作来避免内核开销,这些操作与SplitFS有一些相似之处。虽然这些系统共享在内核和用户空间之间划分任务的相同想法,但KucoFS的不同之处在于,它在执行密切协作的同时展示了细粒度的职责划分。
持久内存存储系统。除了前面提到的持久化内存文件系统,我们在这里总结了更多的PM系统。首先,一般的PM优化。Yang等人从微观和宏观层面探讨了Optane DCPMM的性能特性和特点,并提供了一系列的指导方针,以实现性能的最大化。Libnvmmio通过崩溃原子性扩展了用户空间内存映射I/O。最近的许多论文也设计了各种数据结构,它们在持久内存中正确而有效地工作。第二,PM感知的文件系统。BPFS采用短路影子分页,保证元数据和数据的一致性。SCMFS通过在现有操作系统中使用虚拟内存管理(VMM)将文件映射到相邻的虚拟地址区域,从而简化了文件管理。NOVA-Fortis通过提供快照机制进一步提高了容错能力。Ziggurat是一个分级文件系统,用于估计文件数据的冷热,并将冷数据从PM迁移到磁盘。DevFS将文件系统实现推送到具有计算能力和设备级RAM的存储设备中。第三,分布式PM系统。Hotpot使用分布式共享持久内存架构管理集群中不同节点的PM设备。Octopus通过减少软件开销,利用PM和RDMA来构建一个高效的分布式文件系统。类似地,Orion也是分布式持久内存文件系统,但构建在内核中。FlatStore是一个基于RDMA网络的日志结构键值存储引擎;它通过批量处理小请求最小化刷新开销。
7. 总结
在本文中,我们引入了一个名为Kuco的内核和用户级协同架构,它在用户空间和内核之间展示了细粒度的任务划分。在Kuco的基础上,我们进一步设计并实现了一个名为KucoFS的PMfile系统,实验表明,KucoFS提供了高效和高可伸缩性的性能。